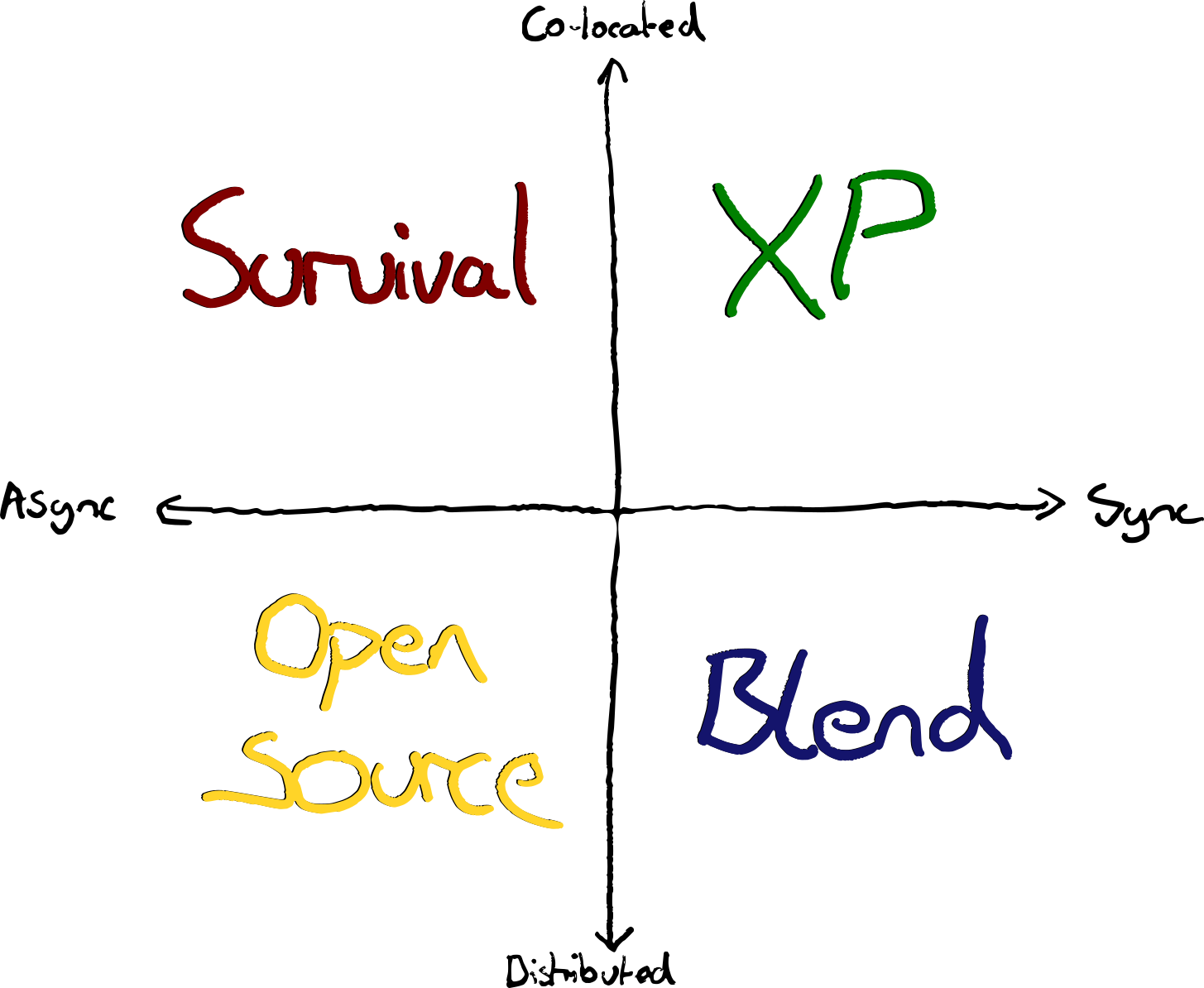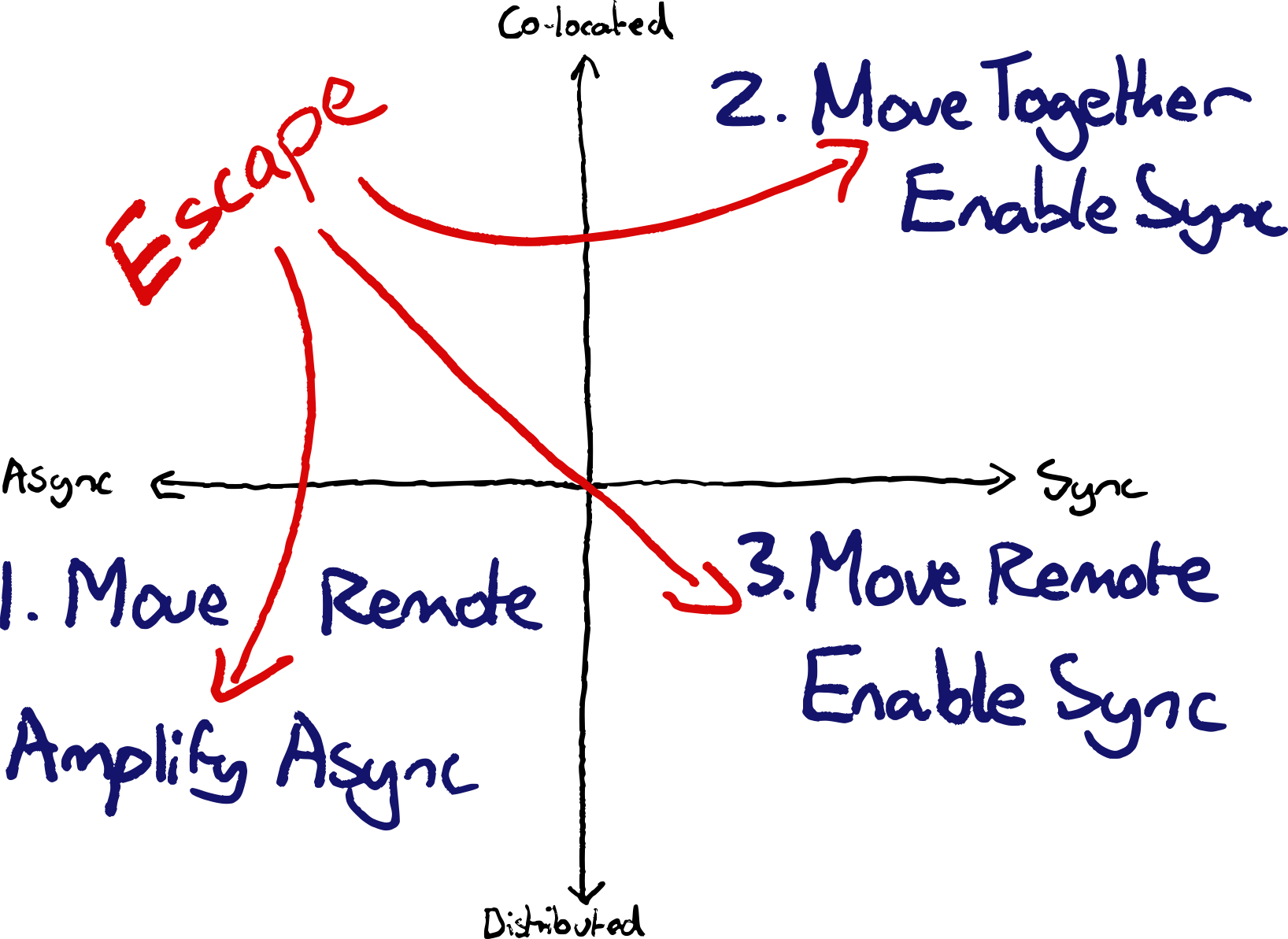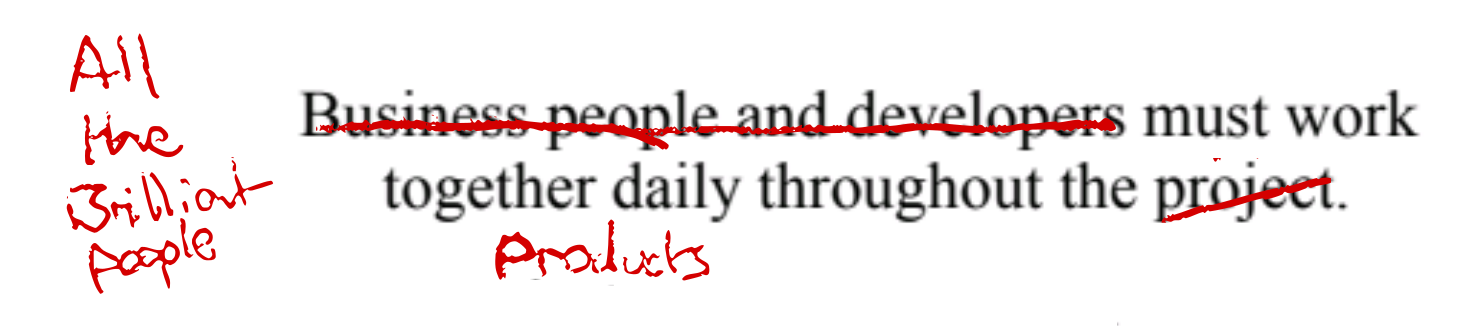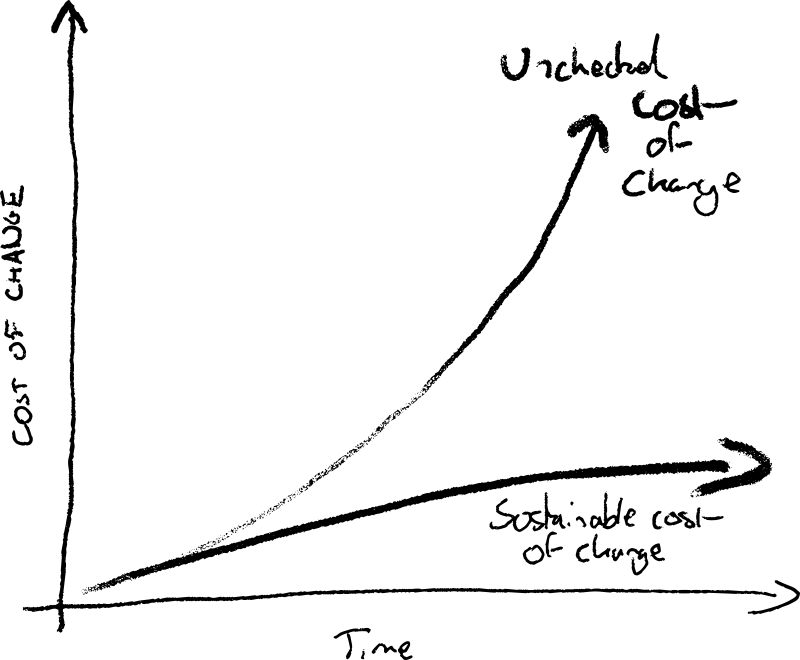
It’s 10 years since I posted about what I shortsightedly called modern extreme programming. Long time XP teams had turned up the dials on what worked, finding more extremely effective ways of building in concert with technology. Technology change from Cloud, IaC, SaaS, Observability and more enabled XP teams to “turn up the dials” on collaboration.
In the decade since, we’ve had arguably even more change to embrace.
There have been highly impactful social changes: from the just-throw-money-at-it trend of the late ZIRP era. The forced remote shock caused by the pandemic. Then the social contagions of return to office, copycat mass layoffs, and (more worryingly) return to bigotry.
Cloud development environments are now viable, and tooling for remote collaboration has improved to the point where XP practices are as viable for remote teams as in-person.
Right now we’re in the process of discovering just how much coding agents, or as Kent Beck calls them: “genies” can accelerate our work. Through building with agents, we’re uncovering how these marvellous tools will shape the future of software development.
After so much change, do XP collaborative practices still make sense, or have the machines and the managers got it from here? Do the revolutionary capabilities of LLMs, and the new economic reality call for reverting to taylorist management? Are we now back to coordinating hyper efficient development factories, or can collaborative development teams still be more effective?
Do XP collaborative practices still make sense, or have the machines and the managers got it from here?
One of the perks of doing a startup is that I’ve been having fun getting my hands dirty building software again. I’m experiencing for myself what it’s like building with coding agents. I’ve also spent the past few years working with teams that avoid as well as those that embrace and benefit from XP practices. It appears to me that XP values, principles, and practices can be as much of an accelerator of human potential as ever. Further, they may provide an even greater advantage amid today’s social and technological challenges and opportunities.
Help people; help the genies
The XP values of Simplicity, Communication, and Feedback (in particular) are grounded in compassion and humility. Compassion for our colleagues and future selves. Helping ourselves continue to work effectively with the systems we’re building, not just solve the immediate problem as swiftly as possible.
This manifests in working in very small steps, so we can get feedback from our tests, others in the team, our customers, and production systems. Continually validating that we’re headed in the right direction. We can adjust course if we’re not, and resolve potential conflicts before they become painful.
We also refactor continuously, simplifying as we go, deleting code, embedding our improved understanding of the system back into the code. We do this so that our future selves and colleagues have the best chance of changing it when we learn how we’re wrong right now. Because we will be wrong.
We build the simplest possible thing that could work right now. Avoiding engineering for future concerns that may not happen. We’ll probably be wrong about those future concerns anyhow, and everything we build now is more context that we have to understand and maintain in future.
We continuously integrate our code, shipping changes to each other (and ideally production) every few minutes, so we can collaborate effectively—anyone else working with us having up to date context.
We pair-program to continuously review each other’s code to avoid mistakes happening in the first place, rather than trying to correct them at review time.
Sad that it has taken the hype of llm coding agents to incentive some folks to prioritise the same things that they could do compassion for their fellow human team-mates. Small steps, small codebases, fast tests, automation, clear code & docs; all help the bots as well as the team.
— Benji Weber (@benjiweber.com) May 29, 2025 at 9:56 AM
All of these practices are also things help work effectively with coding agents; just as they help to work effectively with fellow developers.
Keeping code simple keeps context small, helping more relevant information fit in the LLM context window.
Coding agents are able to make significant changes faster, making continuous integration even more crucial. Faster change will make late integration and conflict resolution even more painful.
Coding agents will happily go off from a short prompt and try and build an entire feature, but with the same risks as when people do that. Sometimes they get it right; often they don’t. Often they’ve misunderstood. Often it appears to work, but has a lot of subtle bugs. Often it will break existing functionality. The genies benefit from fast feedback on small iterations just as much as people do.
TDDing with coding agents keeps them on track, a failing test allows the bots to loop until it finds a working solution to a small increment of behaviour. The steps of: define behaviour, make it work, then make it simpler, help break down each unit of progress into focused tasks that agents can handle more easily.
Pairing with coding agents you can spot where they’re working towards the wrong goal and steer them back.
All of these practices—working in small steps and keeping things simple—will help your coding genies, just as they also help your future self and colleagues.
Do more with less… money, not resilience
Unrelenting pressure for efficiency and recurrent layoffs can strip a lot of resilience from our organisations; tearing apart the networks of relationships and knowledge that have built up in teams.
It may be more efficient to have just one person who understands a service well enough to keep it running. It’s not very resilient to the unexpected—like that person winning the lottery.
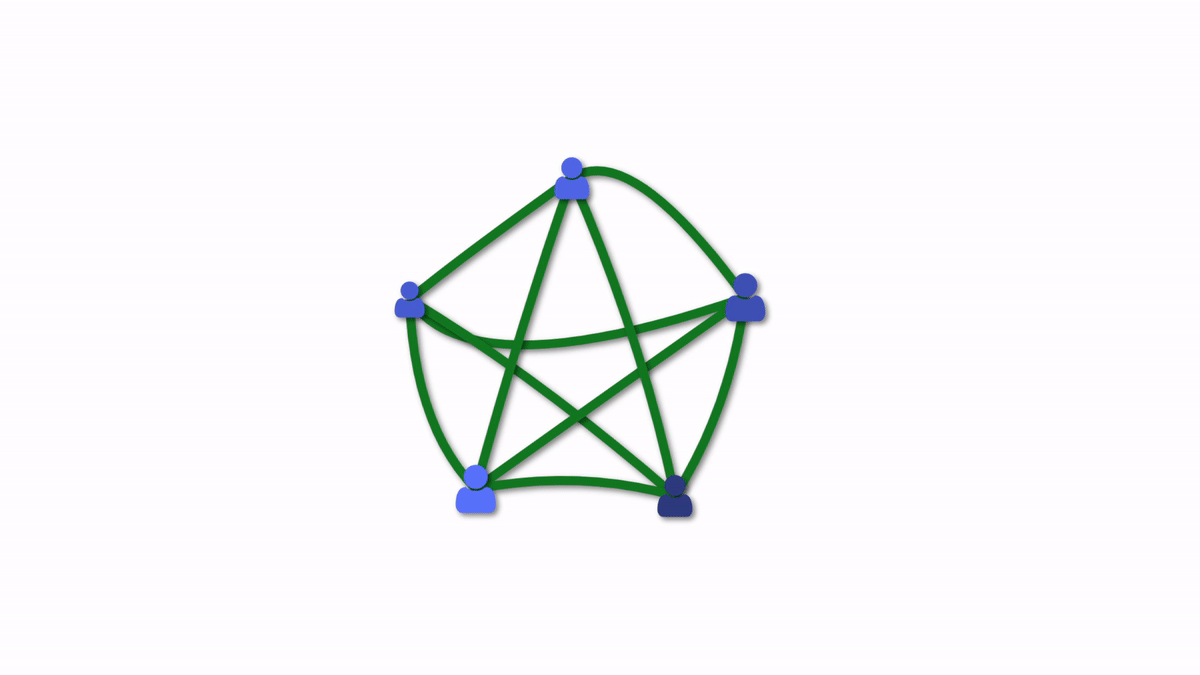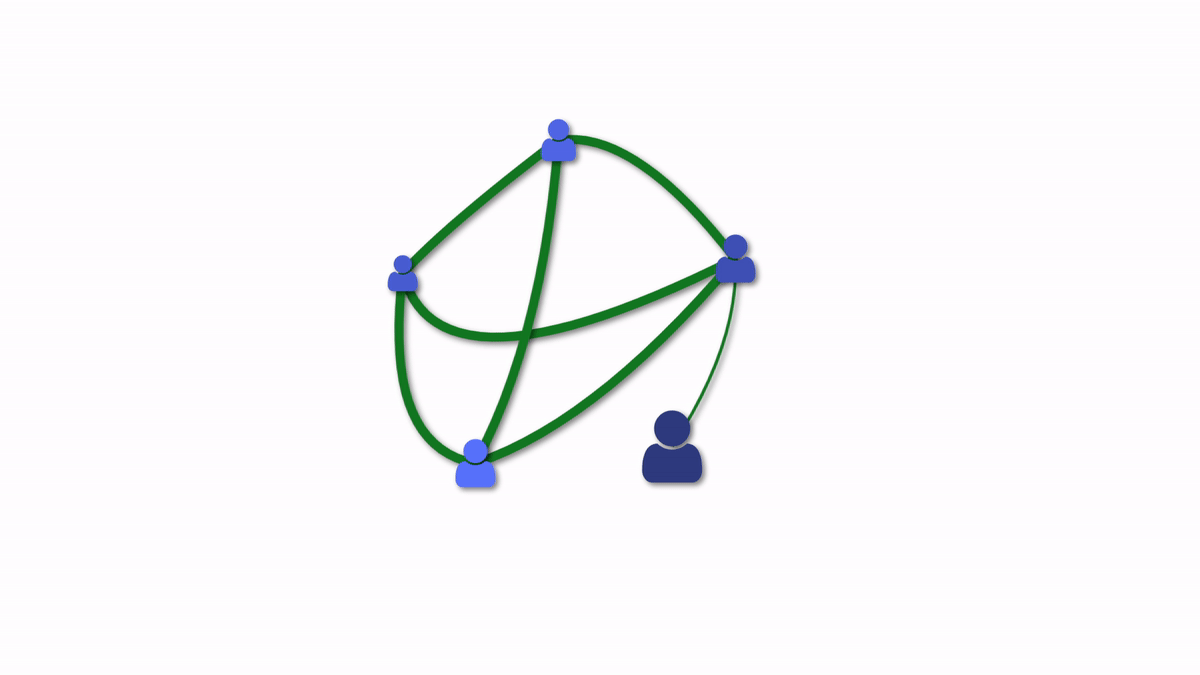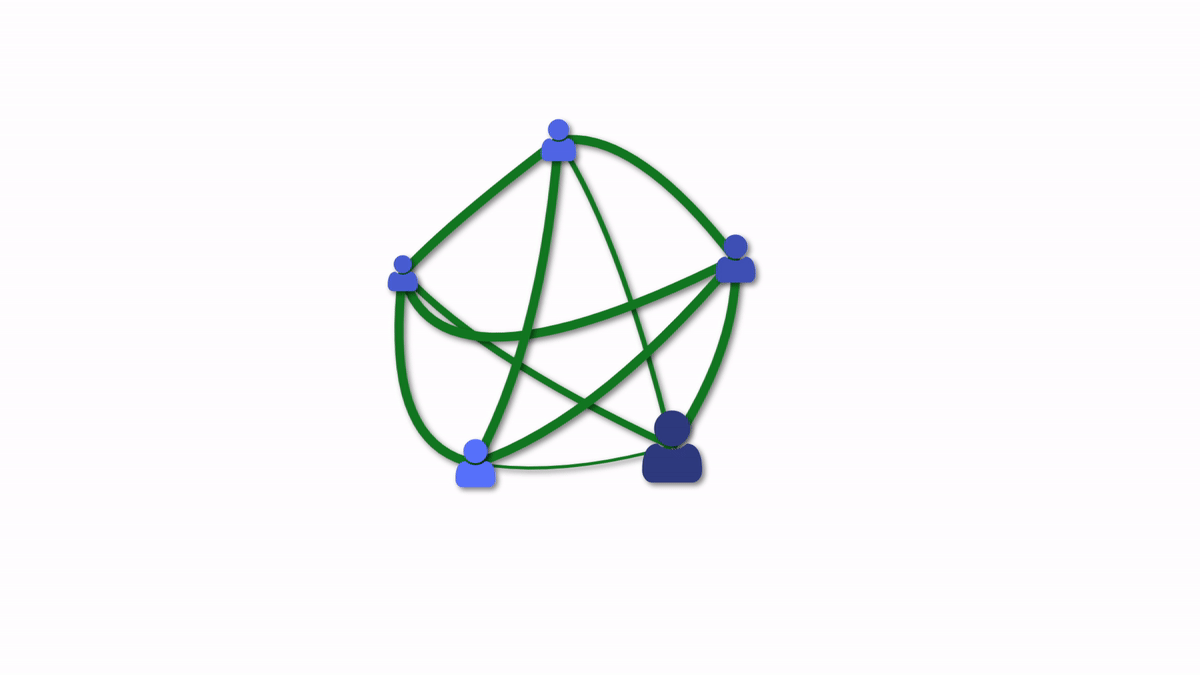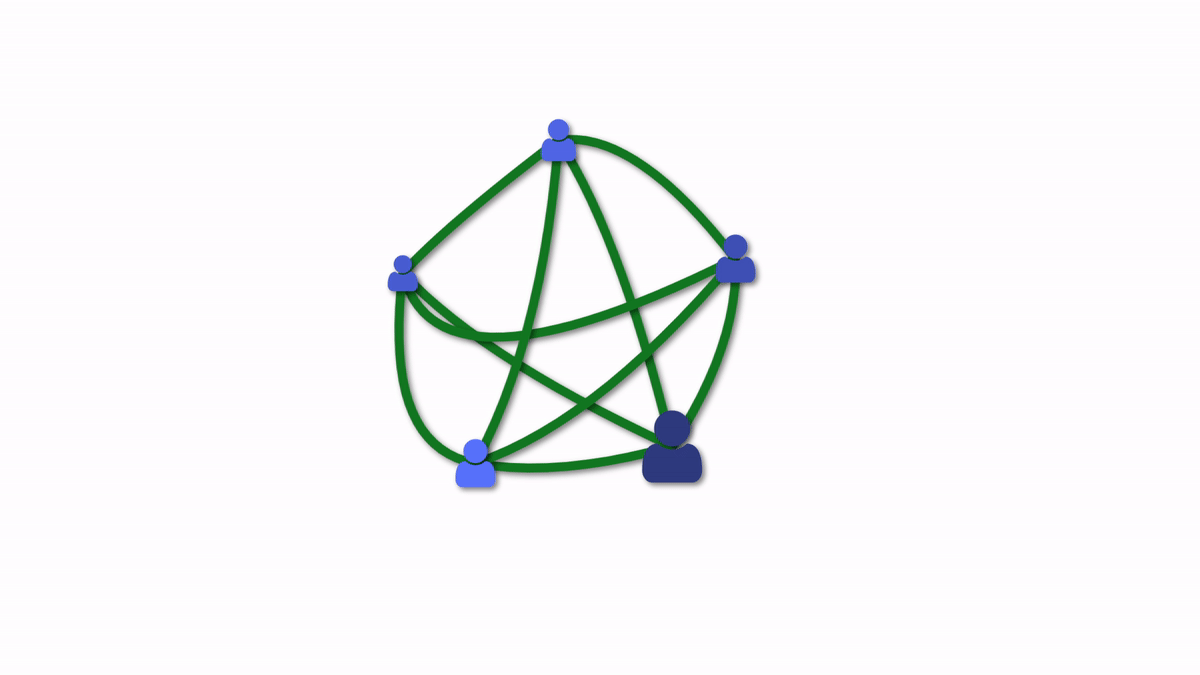
With fewer people, and more constrained resources—collective ownership and understanding of systems is even more important. We can no longer rely on the probability that multiple people in a large team will be able to help in any situation. We have to get more strategic and serendipity is not a strategy.
With the rise of coding agents we’re delegating more and more of the work of building systems to the genies. Without intentionally building resilience into our organisations, we can end up in the situation where no person really understands how the systems our organisation depends upon work. We can build systems faster than ever, with less expertise, but how well can we respond when the unexpected happens? How quickly can the human responders build context on the systems built by genies when a major incident occurs?
XP practices make small teams unreasonably effective at building and running complex systems. The growing pressure to do more with fewer people, and growing ability to do more with fewer people (thanks to agents) only amplifies the benefits of these practices that help fewer people handle more complexity.
The pace of change per employee has increased substantially; XP practices help us embrace change.
Pair or ensemble programming with more than one person (regardless of whether assisted by genies or not) enables resilience through multiple people understanding each change, from the outset.
One way we’ve discovered to up the dial of collective understanding of code is through collective code review. Many teams use code review as a gate for integrating changes, which both delays integration and sets up adversarial incentives of one party trying to integrate a change, while the other party tries to ensure quality. Gating code reviews are not set up to optimise for collective learning, regardless of where your team lands on the scale from the extreme of “LGTM” reviews, to blocking changes pending perfection. Code review sessions where the team reviews code that’s already integrated allow for focus on learning about how it works, and how it can be improved. It’s easier to focus on learning and understanding, without the challenge of juggling priorities and mixed incentives.
TDD and monitoring/observability driven development give us a safety net with fast feedback when something unexpected happens with our systems. We increase our chances that when something goes wrong with the breakneck speed we’re building at nowadays, we immediately know what happened. They also help us validate emergency fixes when we’re responding to an incident without the guesswork.
Discontinuous Learning
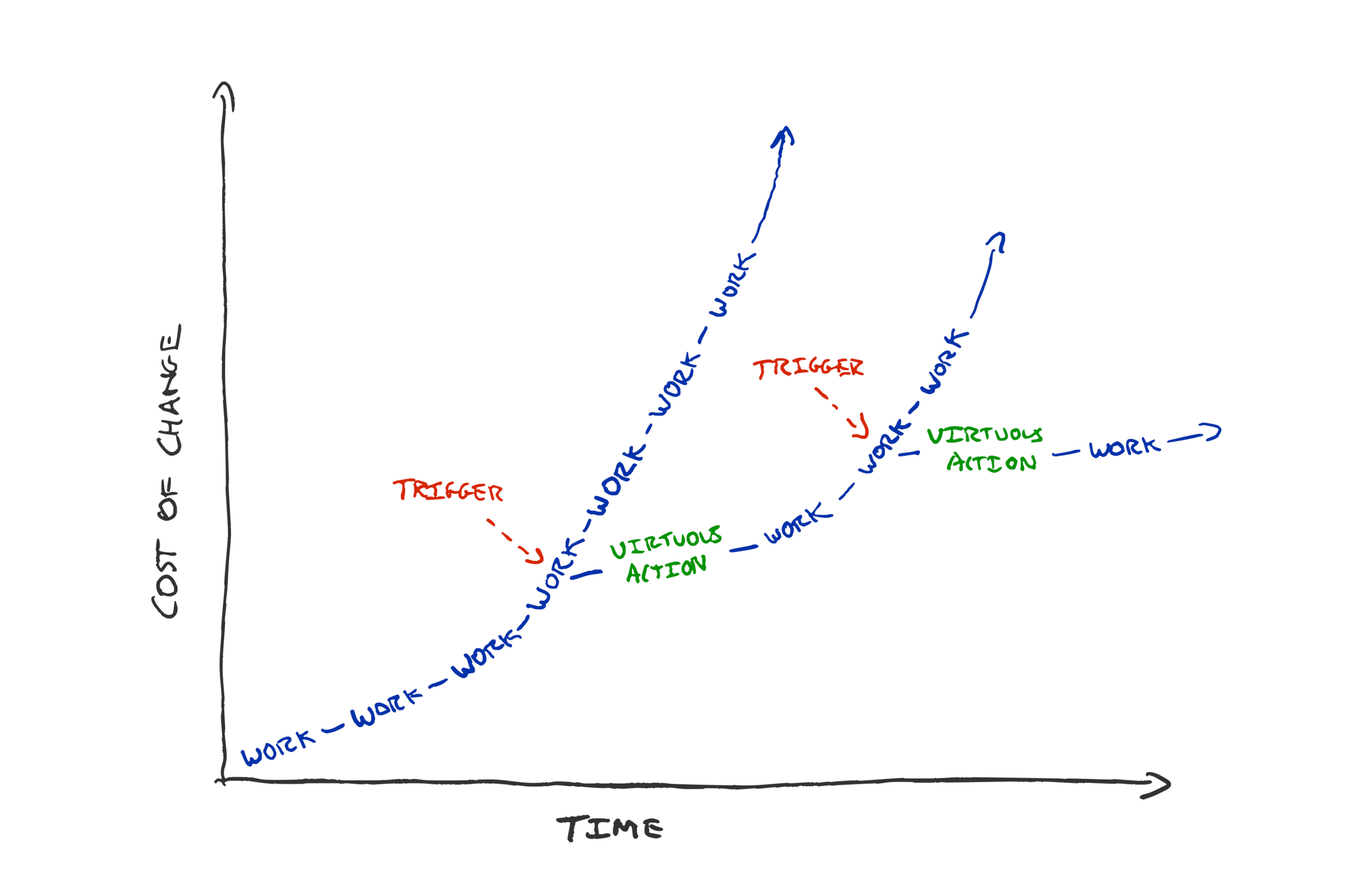
We live in interesting times where teams are being pressured to do more with less and move faster. Concurrently, the rapid evolution of developer tooling means each week there are ways to solve problems faster.
The irony is that the pressure to do more with less, incentivises teams to go heads-down and build as fast as possible. They risk missing transformational improvements that provide better ways of solving their problems.
We often call a learning culture continuous learning, but when pressures are high, it’s actually discontinuous and regular learning that helps sustain the pace. Focus on building when you’re building, focus on learning when you’re learning.
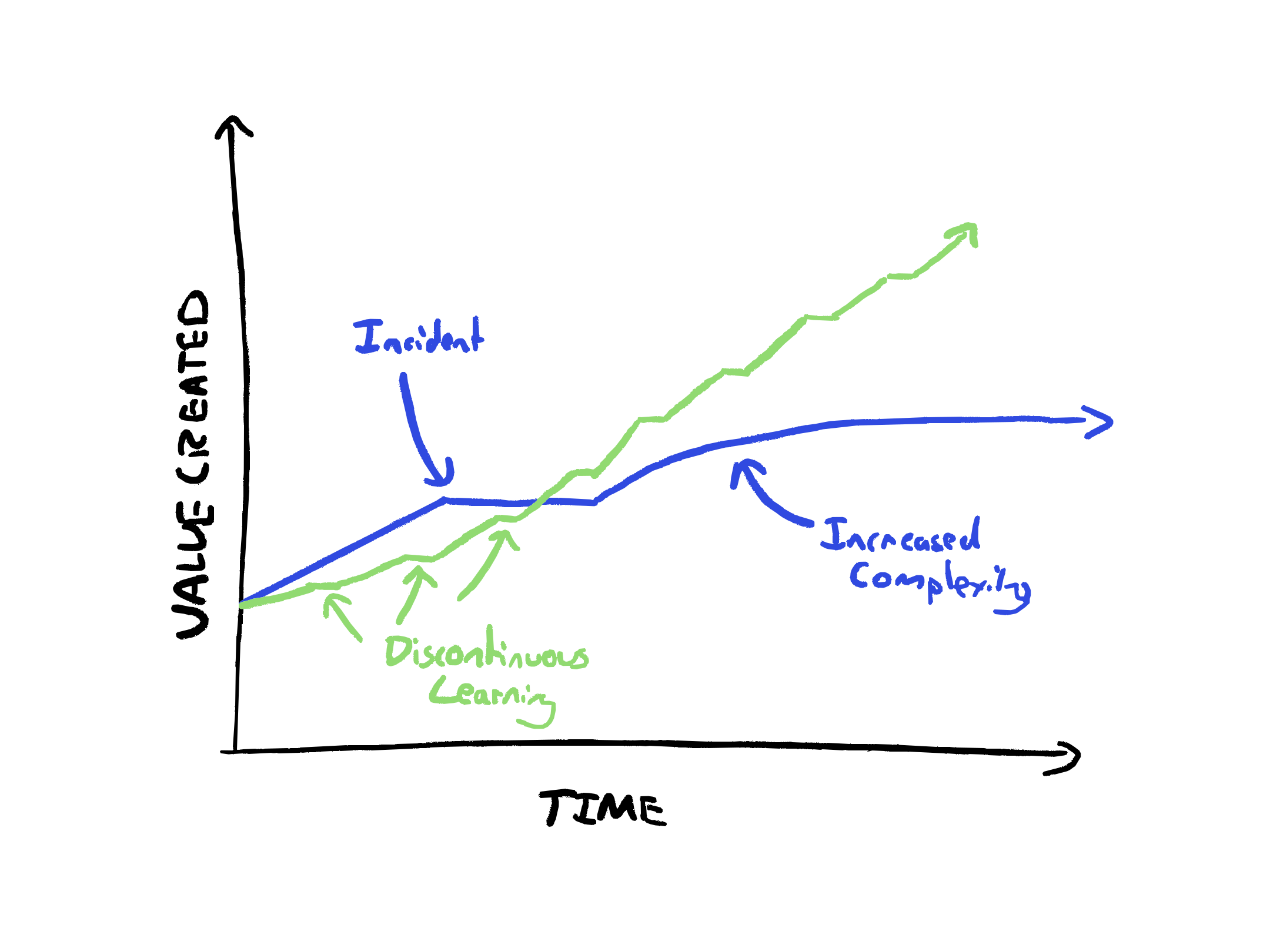
Build healthy habits that give regular learning-focused time. e.g.
- Allocate a day a week to find better ways of working
- Spend two days between features on focused learning
- Have a weekly code safari, exploring and learning from code together
- Use a rota to avoid forgetting learning oriented work
- Nominate a person from the team to join a customer call every week
These are not continuous activities that can be crowded out. They are intentionally established habits where we choose to make time for learning and don’t allow the ever present urgency to distract us from the long term sustainable pace.
When the pace of change is so high, the teams that embrace learning will win in the long run. Learning teams will outpace teams that ship slightly more this week, but miss an opportunity the next.
Resilience is a Competitive Advantage
The pace of change for development teams feels higher than ever, and so XP’s tactics for helping teams embrace change are more helpful than ever.
I’m finding that XP practices don’t just help people work better together, they make AI coding agents more effective as well.
Working collaboratively, in small steps, and optimising for learning, helps build resilience in small teams. This is more valuable than ever at a time where teams are being stretched leaner and leaner.
The incentives from fast coding agents, and markets rewarding leanness can lead to brittleness that cannot cope with the unexpected. XP can provide a competitive advantage.