I love SQL, despite its many flaws.
Much is argued about functional programming vs object oriented. Different ways of instructing computers.
SQL is different. SQL is a language where I can ask the computer a question and it will figure out how to answer it for me.
Fluency in SQL is a very practical skill. It will make your life easier day to day. It’s not perfect, it has many flaws (like null) but it is in widespread use (unlike, say, prolog or D).
Useful in lots of contexts
As an engineer, sql databases often save me writing lots of code to transform data. They save me worrying about the best way to manage finite resources like memory. I write the question and the database (usually) figures out the most efficient algorithm to use, given the shape of the data right now, and the resources available to process it. Like magic.
SQL helps me think about data in different ways, lets me focus on the questions I want to ask of the data; independent of the best way to store and structure data.
As a manager, I often want to measure things, to know the answer to questions. SQL lets me ask lots of questions of computers directly without having to bother people. I can explore my ideas with a shorter feedback loop than if I could only pose questions to my team.
SQL is a language for expressing our questions in a way that machines can help answer them; useful in so many contexts.
It would be grand if even more things spoke SQL. Imagine you could ask questions in a shell instead of having to teach it how to transform data
Why do we avoid it?
SQL is terrific. So why is there so much effort expended in avoiding it? We learn ORM abstractions on top of it. We treat SQL databases as glorified buckets of data: chuck data in, pull data out.
Transforming data in application code gives a comforting amount of control over the process, but is often harder and slower than asking the right question of the database in the first place.
Do you see SQL as a language for storing and retrieving bits of data, or as a language for expressing questions?
Let go of control
The database can often figure out the best way of answering the question better than you.
Let’s take an identical query with three different states of data.
Here’s two simple relations with 1 attribute each. a and b. With a single tuple in each relation.
CREATE TABLE a(id INT); CREATE TABLE b(id INT); INSERT INTO a VALUES(1); INSERT INTO b VALUES(1); EXPLAIN analyze SELECT * FROM a NATURAL JOIN b; |
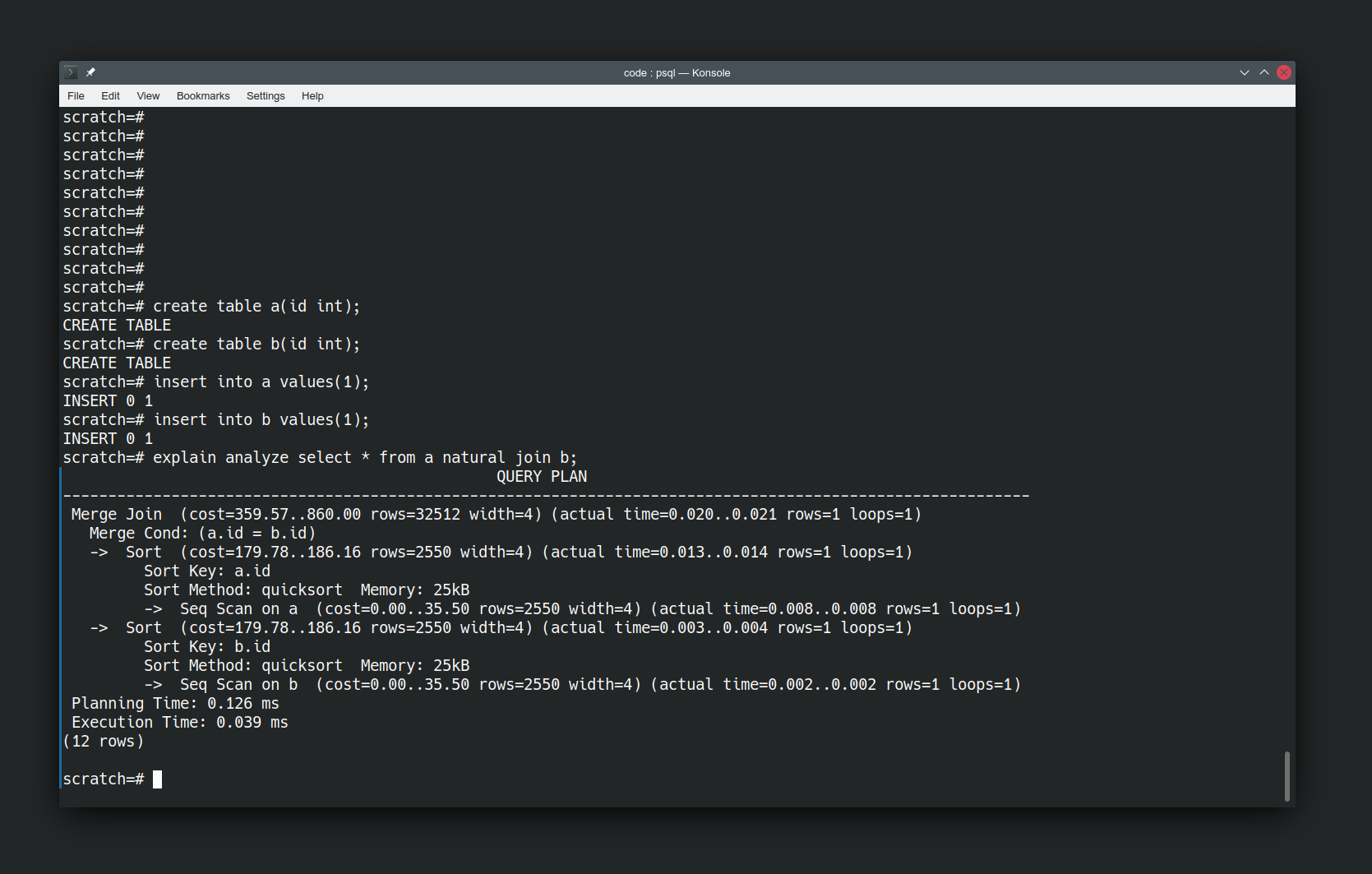
“explain analyze” is telling us how postgres is going to answer our question. The operations it will take, and how expensive they are. We haven’t told it to use quicksort, it has elected to do so.
Looking at how the database is doing things is interesting, but let’s make it more interesting by changing the data. Let’s add in a boatload more values and re-run the same query.
INSERT INTO a SELECT * FROM generate_series(1,10000000); EXPLAIN analyze SELECT * FROM a NATURAL JOIN b; |
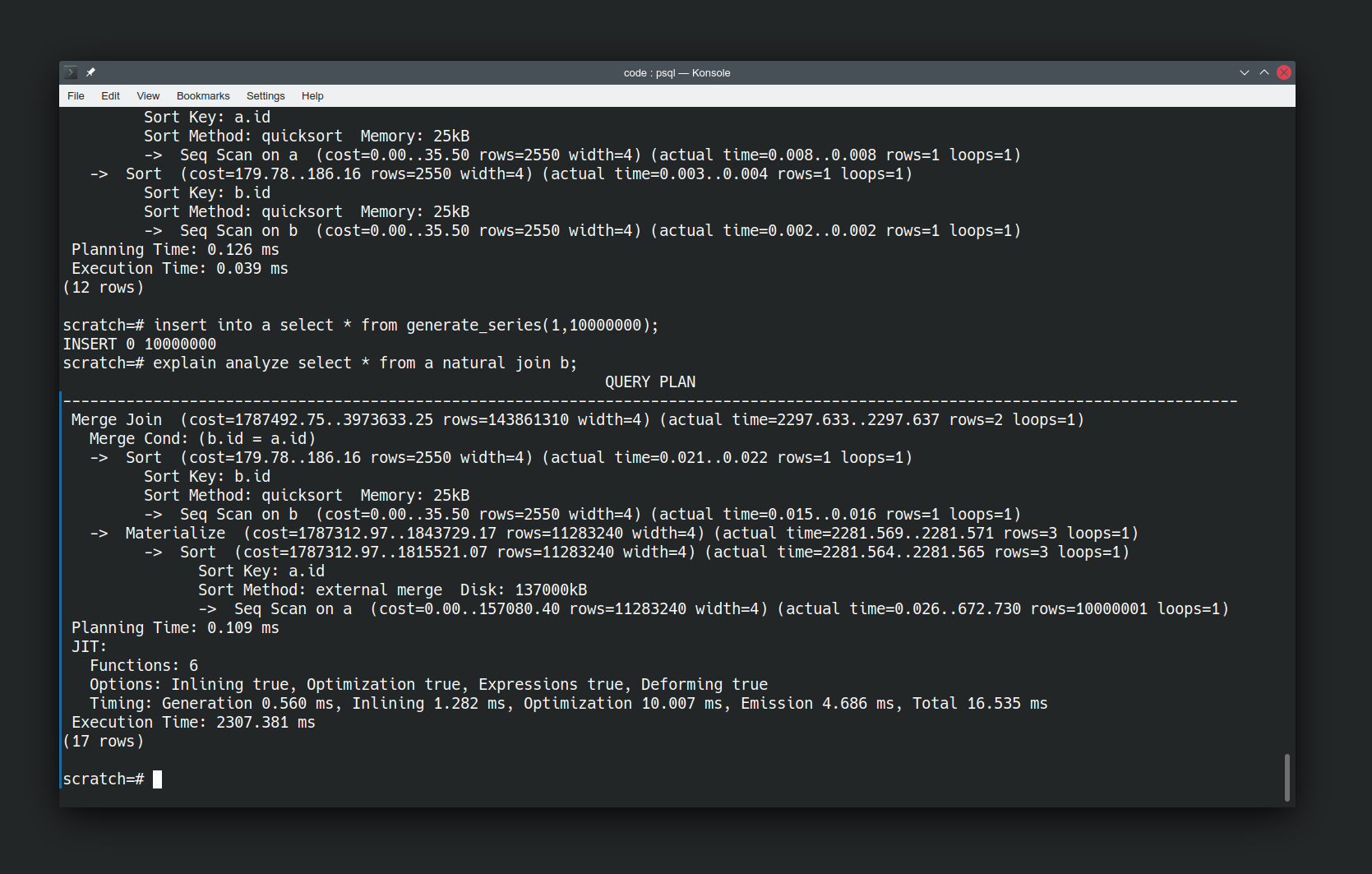
We’ve used generate_series to generate ten million tuples in relation ‘a’. Note the “Sort method” has changed to use disk because the data set is larger compared to the resources the database has available. I haven’t had to tell it to do this. I just asked the same question and it has figured out that it needs to use a different method to answer the question now that the data has changed.
But actually we’ve done the database a disservice here by running the query immediately after inserting our data. It’s not had a chance to catch up yet. Let’s give it a chance by running analyze on our relations to force an update to its knowledge of the shape of our data.
analyze a; analyze b; EXPLAIN analyze SELECT * FROM a NATURAL JOIN b; |
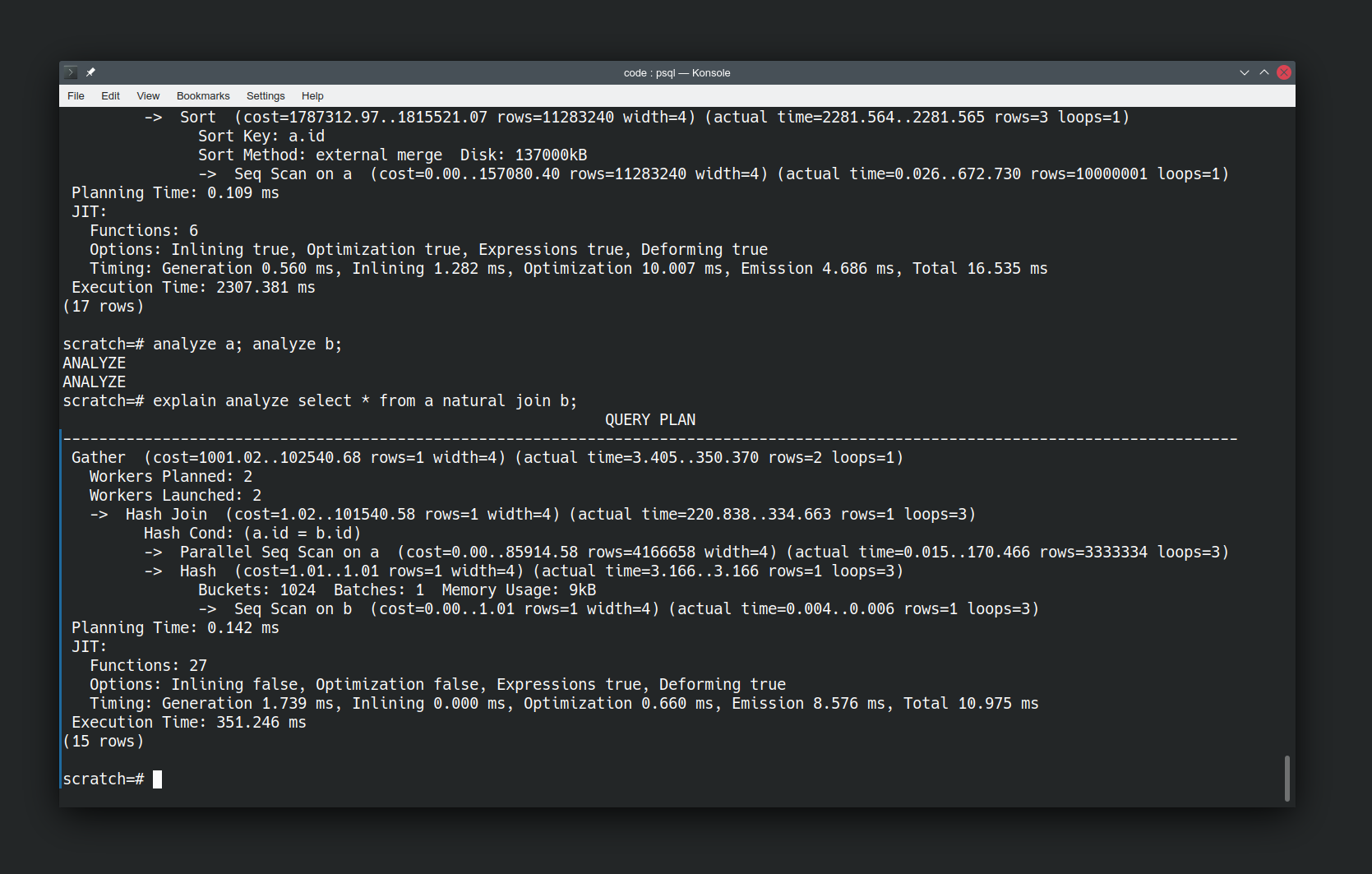
Now re-running the same query is a lot faster, and the approach has significantly changed. It’s now using a Hash Join not a Merge Join. It has also introduced parallelism to the query execution plan. It’s an order of magnitude faster. Again I haven’t had to tell the database to do this, it has figured out an easier way of answering the question now that it knows more about the data.
Asking Questions
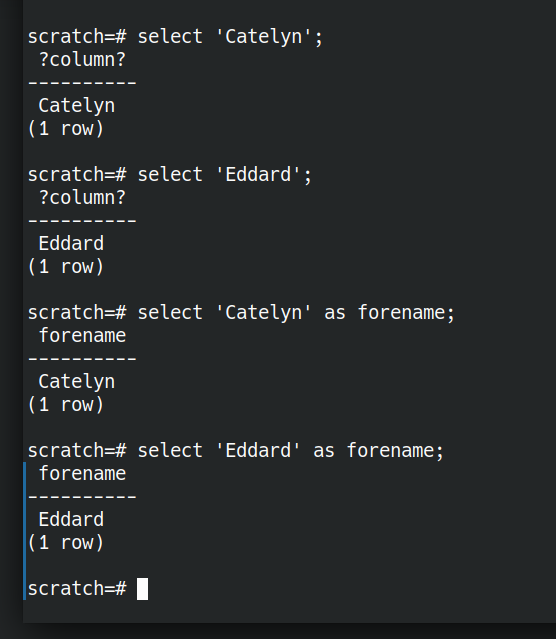
Let’s look at some of the building blocks SQL gives us for expressing questions. The simplest building block we have is asking for literal values.
SELECT 'Eddard'; SELECT 'Catelyn'; |
A value without a name is not very useful. Let’s rename them.
SELECT 'Eddard' AS forename; SELECT 'Catelyn' AS forename; |
What if we wanted to ask a question of multiple Starks: Eddard OR Catelyn OR Bran? That’s where UNION comes in.
SELECT 'Eddard' AS forename UNION SELECT 'Catelyn' AS forename UNION SELECT 'Bran' AS forename; |

We can also express things like someone leaving the family. With EXCEPT.
SELECT 'Eddard' AS forename UNION SELECT 'Catelyn' AS forename UNION SELECT 'Bran' AS forename EXCEPT SELECT 'Eddard' AS forename; |

What about people joining the family? How can we see who’s in both families. That’s where INTERSECT comes in.
( SELECT 'Jamie' AS forename UNION SELECT 'Cersei' AS forename UNION SELECT 'Sansa' AS forename ) INTERSECT ( SELECT 'Sansa' AS forename ); |

It’s getting quite tedious having to type out every value in every query already.
SQL uses the metaphor “table”. We have tables of data. To me that gives connotations of spreadsheets. Postgres uses the term “relation” which I think is more helpful. Each “relation” is a collection of data which have some relation to each other. Data for which a predicate is true.
Let’s store the starks together. They are related to each other.
CREATE TABLE stark AS SELECT 'Sansa' AS forename UNION SELECT 'Eddard' AS forename UNION SELECT 'Catelyn' AS forename UNION SELECT 'Bran' AS forename ; CREATE TABLE lannister AS SELECT 'Jamie' AS forename UNION SELECT 'Cersei' AS forename UNION SELECT 'Sansa' AS forename; |
Now we have stored relations of related data that we can ask questions of. We’ve stored the facts where “is a member of house stark” and “is a member of house lannister” are true. What if we want people who are in both houses. A relational AND. That’s where NATURAL JOIN comes in.
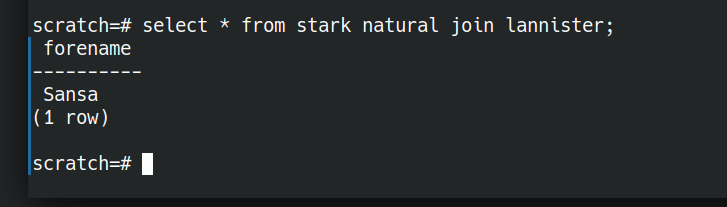
NATURAL JOIN is not quite the same as the set based and (INTERSECT above). NATURAL JOIN will work even if there are different arity tuples in the two relations we are comparing.
Let’s illustrate this by creating a relation pet with two attributes.
create table pet as
CREATE TABLE pet AS SELECT 'Sansa' AS forename, 'Lady' AS pet UNION SELECT 'Bran' AS forename, 'Summer' AS pet; |
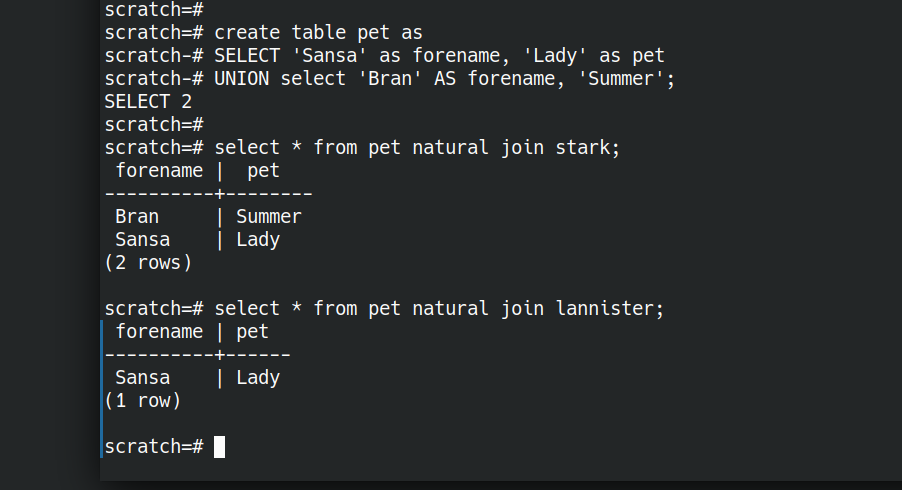
Now we have an AND, what about OR? We have a set-or above (UNION). I think the closest thing to a relational OR is a full outer join.
CREATE TABLE animal AS SELECT 'Lady' AS forename, 'Wolf' AS species UNION SELECT 'Summer' AS forename, 'Wolf' AS species; SELECT * FROM stark FULL OUTER JOIN animal USING(forename); |
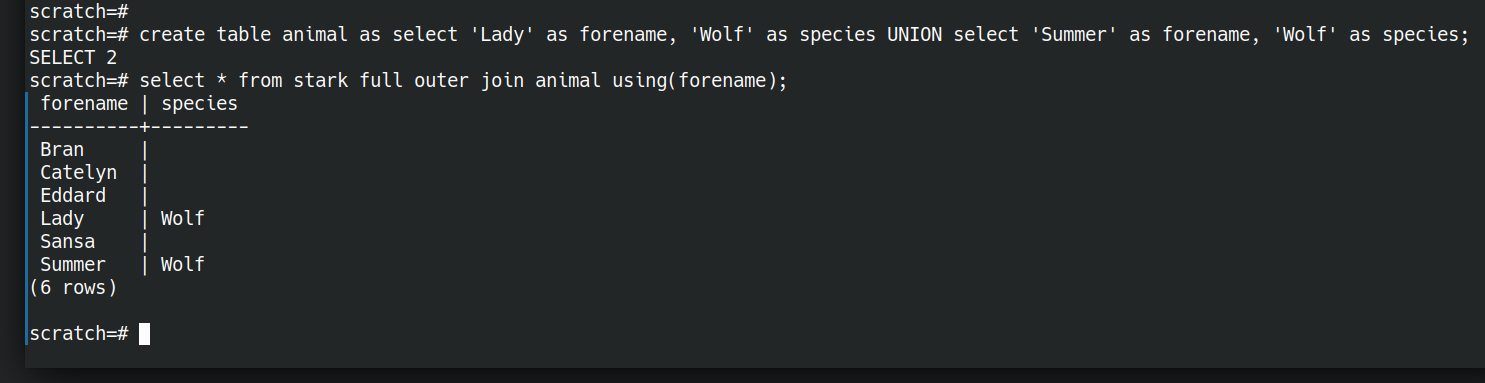
Ok so we can ask simple questions with ands and ors. There are also equivalents of most of the relational algebra operations.
What if I want to invade King’s Landing?
What about more interesting questions? We can do those too. Let’s jump ahead a bit.
What if we’re wanting to plan an attack on Kings Landing and need to consider the routes we could take to get there. Starting from just some facts about the travel options between locations, let’s ask the database to figure out routes for us.
First the data.
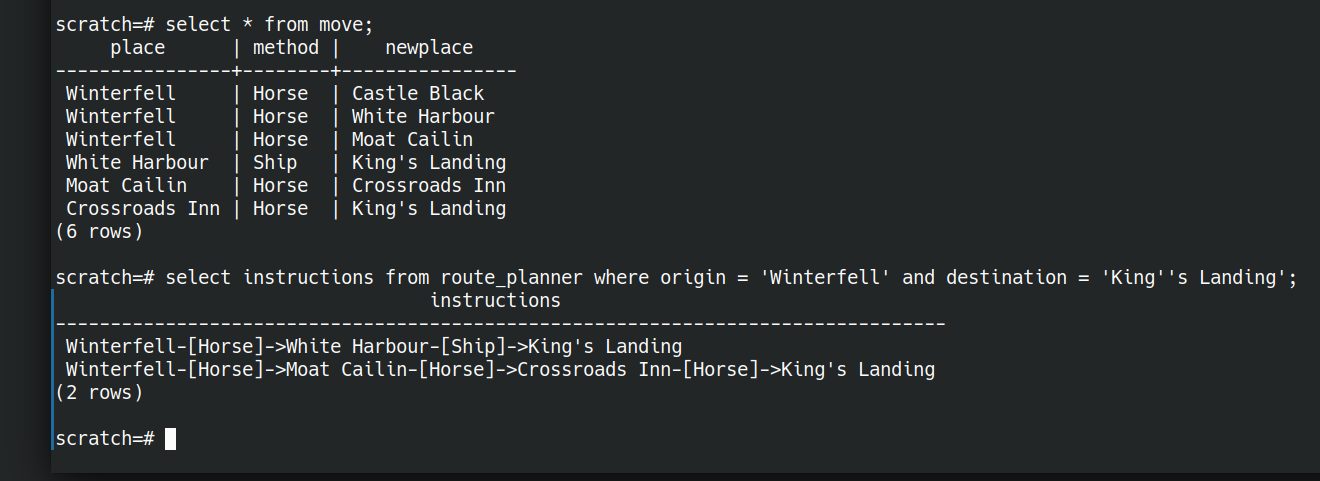
CREATE TABLE move (place text, method text, newplace text); INSERT INTO move(place,method,newplace) VALUES ('Winterfell','Horse','Castle Black'), ('Winterfell','Horse','White Harbour'), ('Winterfell','Horse','Moat Cailin'), ('White Harbour','Ship','King''s Landing'), ('Moat Cailin','Horse','Crossroads Inn'), ('Crossroads Inn','Horse','King''s Landing'); |
Now let’s figure out a query that will let us plan routes between origin and destination as below
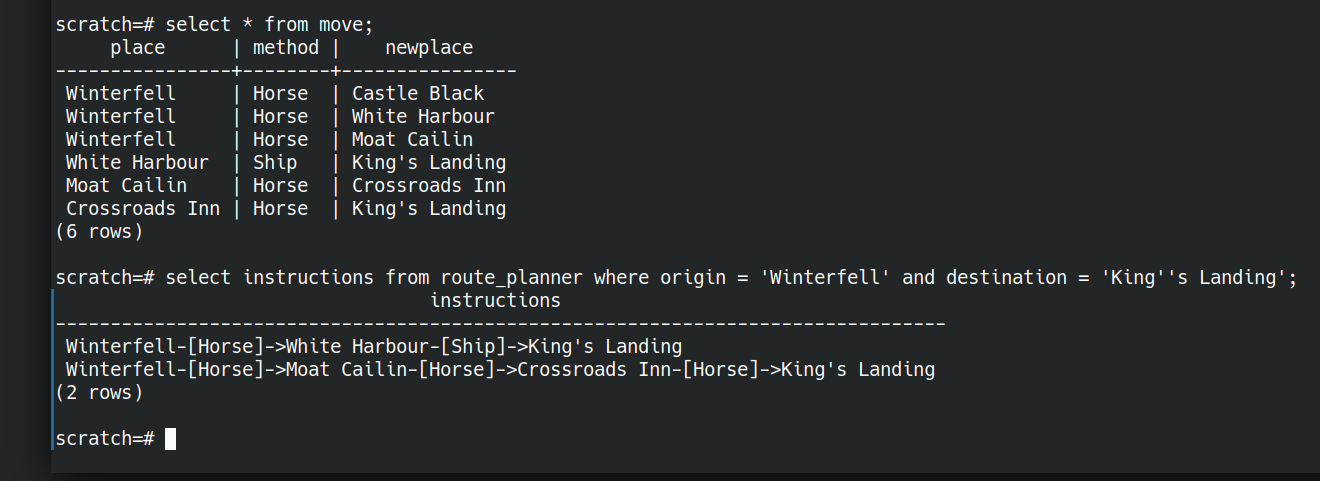
We don’t need to store any intermediate data, we can ask the question all in one go. Here “route_planner” is a view (a saved question)
CREATE VIEW route_planner AS WITH recursive route(place, newplace, method, LENGTH, path) AS ( SELECT place, newplace, method, 1 AS LENGTH, place AS path FROM move --starting point UNION -- or SELECT -- next step on journey route.place, move.newplace, move.method, route.length + 1, -- extra step on the found route path || '-[' || route.method || ']->' || move.place AS path -- describe the route FROM move JOIN route ON route.newplace = move.place -- restrict to only reachable destinations from existing route ) SELECT place AS origin, newplace AS destination, LENGTH, path || '-[' || method || ']->' || newplace AS instructions FROM route; |
I know this is a bit “rest of the owl” compared to what we were doing above. I hope it at least illustrates the extent of what is possible. (It’s based on the prolog tutorial). We have started from some facts about adjacent places and asked the database to figure out routes for us.
Let’s talk it through…
CREATE VIEW route_planner AS |
this saves the relation that’s the result of the given query with a name. We did this above with
CREATE TABLE lannister AS SELECT 'Jamie' AS forename UNION SELECT 'Cersei' AS forename UNION SELECT 'Sansa' AS forename; |
While create table will store a static dataset, a view will re-execute the query each time we interrogate it. It’s always fresh even if the underlying facts change.
WITH recursive route(place, newplace, method, LENGTH, path) AS (...); |
This creates a named portion of the query, called a “common table expression“. You could think of it like an extract-method refactoring. We’re giving part of the query a name to make it easier to understand. This also allows us to make it recursive, so we can build answers on top of partial answers, in order to build up our route.
SELECT place, newplace, method, 1 AS LENGTH, place AS path FROM move |
This gives us all the possible starting points on our journeys. Every place we know we can make a move from.
We can think of two steps of a journey as the first step OR the second step. So we represent this OR with a UNION.
JOIN route ON route.newplace = move.place |
Once we’ve found our first and second steps, the third step is just the same—treating the second step as the starting point. “route” here is the partial journey so far, and we look for feasible connected steps.
path || '-[' || route.method || ']->' || move.place AS path; |
here we concatenate instructions so far through the journey. Take the path travelled so far, and append the next mode of transport and next destination.
Finally we select the completed journey from our complete route
SELECT place AS origin, newplace AS destination, LENGTH, path || '-[' || method || ']->' || newplace AS instructions FROM route; |
Then we can ask the question
SELECT instructions FROM route_planner WHERE origin = 'Winterfell' AND destination = 'King''s Landing'; |
and get the answer
instructions ------------------------------------------------------------------------------- Winterfell-[Horse]->White Harbour-[Ship]->King's Landing Winterfell-[Horse]->Moat Cailin-[Horse]->Crossroads Inn-[Horse]->King's Landing (2 rows)
Thinking in Questions
Learning SQL well can be a worthwhile investment of time. It’s a language in widespread use, across many underlying technologies.
Get the most out of it by shifting your thinking from “how can I get at my data so I can answer questions” to “How can I express my question in this language?”.
Let the database figure out how to best answer the question. It knows most about the data available and the resources at hand.