One of the more interesting questions that came up at Pipeline Conference was:
“How can we mitigate the risk of releasing a change that damages our data?”
When we have a database holding data that may be updated and deleted, as well as inserted/queried, then there’s a risk of releasing a change that causes the data to be mutated destructively. We could lose valuable data, or worse – have incorrect data upon which we make invalid business decisions.
Point in time backups are insufficient. For many organisations, simply being unable to access the missing or damaged data for an extended period of time while a backup is restored, would have an enormous cost. Invalid data used to make business decisions could also result in a large loss.
Worse, with most kinds of database it’s much harder to roll back the database to a point in time, than it is to roll-back our code. It’s also hard to or isolate and roll-back the bad data, while retaining the good data inserted since a change.
How can we avoid release-paralysis when there’s risk of catastrophic data damage if we release bad changes?
Practices like having good automated tests and pair programming may reduce the risk of releasing a broken change – but in the worst-case scenario where they don’t catch a destructive bug, how can we mitigate its impact?
Here’s some techniques I think can help.
Release more Frequently
This may sound counter-intuitive. If every release we make has a risk of damaging our data, surely releasing more frequently increases that risk?
There has been lots written about this. The reality seems to be that the more frequent our releases, the smaller they are, which means the chances of one causing a problem are reduced.
We are able to reason about the impact of a tiny change more easily than a huge change. This helps us to think through potential problems when reviewing before deployment.
We’re also more easily able to confirm that a small change is behaving as expected in production. Which means we should notice any undesirable behaviour more quickly. Especially if we are practising monitoring driven development,
Attempting to release more frequently will likely force you to think about the risks involved in releasing your system, and consider other ways to mitigate them. Such as…
Group Data by Importance
Not all data is equally important. You probably care a lot that financial transactions are not lost or damaged, but you may not care quite so much whether you know when a user last logged into your system.
If every change you release is theoretically able to both update the user’s last logged in date, and modify financial transactions, then there’s some level of risk that it does the latter when you intended it to do the former.
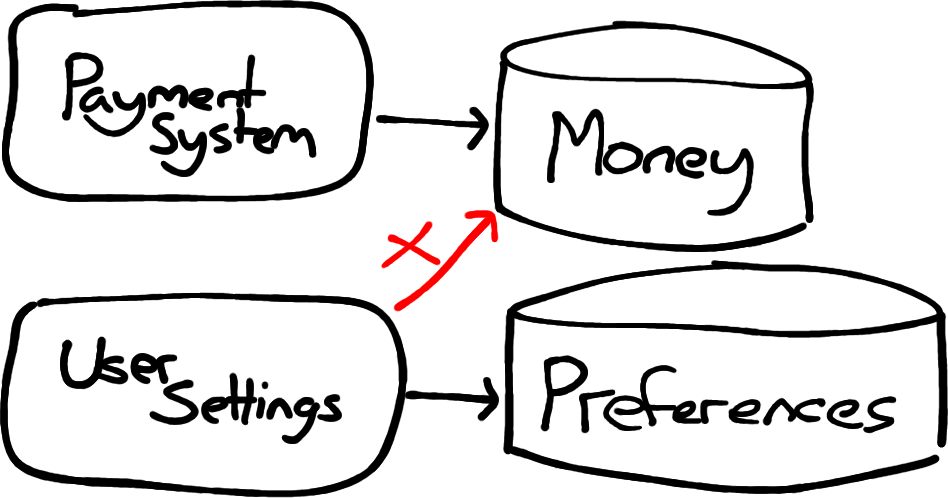
Simply using different credentials and permissions to control which parts of your system can modify what data, can increase your confidence in changing less critical parts of your system. Most databases support quite fine-grained permissions, to restrict what applications are able to do, and you can also physically separate different categories of data.
Separate Reads from Writes
If you separate the responsibilities of reading/writing data into separate applications (or even clearly separated parts of the same application), you can make changes to code that can only read data with more peace of mind, knowing there’s limits to how badly it can go wrong.
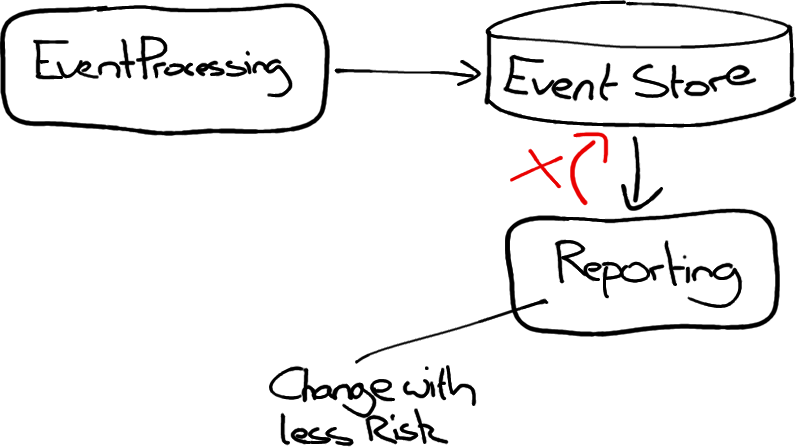
Command Query/Responsibility Separation can also help simplifying conceptual models, and simplify certain performance problems.
Make Important data Immutable
If your data is very important, why allow it to be updated at all? If it can’t be changed, then there’s no risk of something you release damaging it.
There’s no reason you should ever need to alter a financial transaction or the fact that an event has occurred.
There are often performance reasons to have mutable data, but there’s rarely a reason that your canonical datastore needs to be mutable.
I like using append-only logs as the canonical source of data.
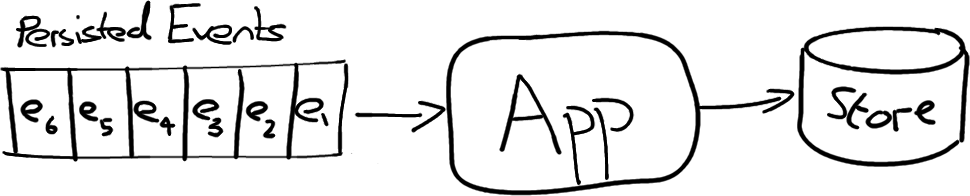
If changes to a data model are made by playing through an immutable log, then we can always recover data by replaying the log with an older snapshot.
If you have an existing system with lots of mutable database state, and you can’t easily change it, you may be able to get some of the benefits by using your database well. Postgres allows you to archive its Write-Ahead-Logs. If you archive a copy of these you can use them to restore the state of the database at any arbitrary point in time, and hence recover data even if it was not captured in a snapshot backup.
Delayed Replicas
Let’s say we mess up really badly and destroy/damage data. Having good snapshot backups probably isn’t going to save us, especially if we have a lot of data. Restoring a big database from a snapshot can take a significant amount of time. You might even have to do it with your system offline or degraded, to avoid making the problem worse.
Some databases have a neat feature of delayed replcation. This allows you to have a primary database, and then replicate changes to copies, some of which you delay by a specified amount of time.
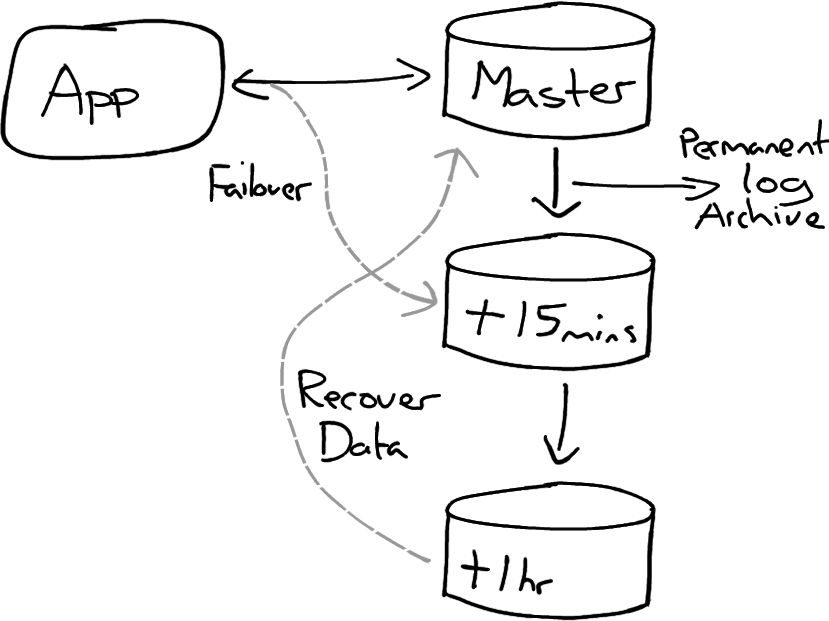
This gives you a window of opportunity to spot a problem. If you do spot a problem you have the option to failover to a slightly old version, or recover data without having to wait for a backup to restore. For example you could have a standby server that is 10 minutes delayed, another at 30mins, and another at an hour.
When you notice the problem you can either failover to the replica or stop replication and merge selected data back from the replica to the master.
Even if your database can’t do this, you could also build it in at the application level. Particularly if your source of truth is a log or event-stream.
Verify Parallel Producers
There will always be some changes that are riskier than others. It’s easy to shy away from updating code that deals with valuable data. This in turn makes the problem worse, it can lead to the valuable code being the oldest and least clean code in your system. Old and smelly code tends to be riskier to change and release.
Steve Smith described an application pattern called verify branch by abstraction that I have used successfully to incrementally replace consumers of data, such as reporting tools or complex calculations.
A variation of this technique can also be used to incrementally and safely make large, otherwise risky changes, to producers of data. i.e. things that might need to write to stores of important data and can potentially damage them.
In this case we fork our incoming data just before the point at which we want to make a change. This could be achieved by sending HTTP requests to multiple implementations of a service, by having two implementations of a service ingesting different event logs, or simply having multiple implementations of an interface within an application, one of which delegates to both the old and new implementation.
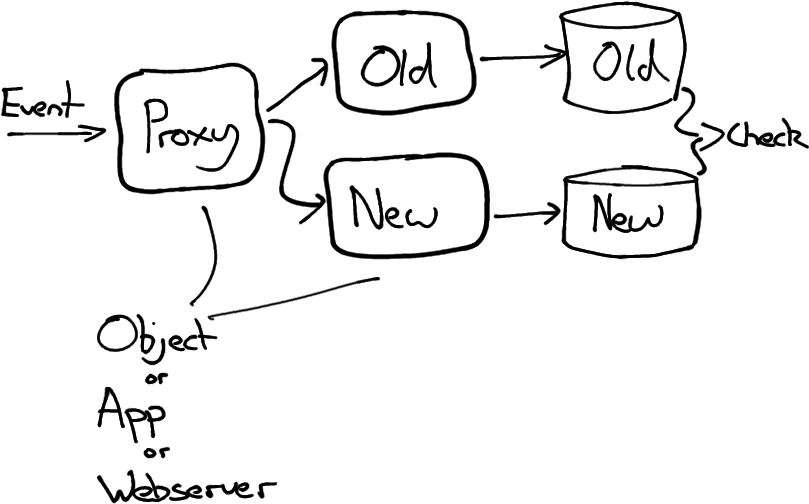
At whatever stage we fork our input, we write the output to a separate datastore that is not yet used by our application.
We can then compare the old and new datastore after leaving it running in parallel for a suitable amount of time.
If we are expecting it to take some time to make our changes, it may be worth automating this comparison of old and new. We can have the application read from both the old and the new datastores, and trigger an alert if the results differ. If this is too difficult we could simply automate periodic comparisons of the datastores themselves and trigger alerts if they differ.
Summary
If you’re worried about the risk to your data of changing your application, look at how you can change your design to reduce the risk. Releasing less frequently will just increase the risk.