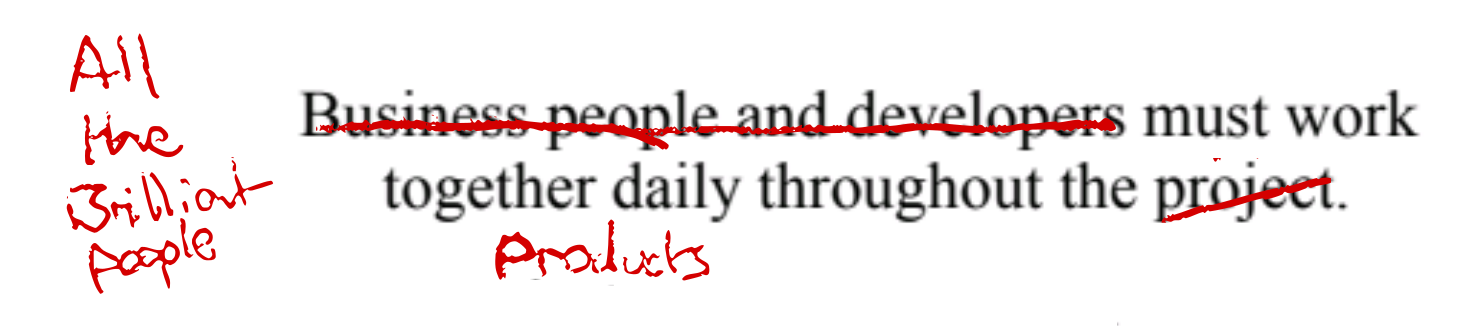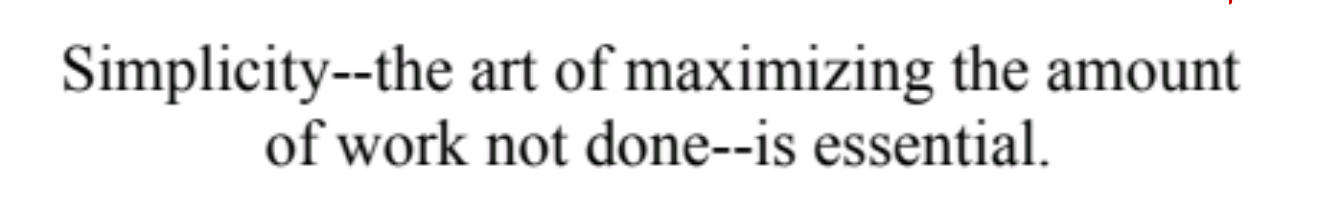Spoilers: it’s not about whether remote or office work is better.
The prevalence of return to office mandates has provoked much discourse and strong opinions. For good reasons. Return to office mandates can tear teams apart by pushing out people who cannot relocate, at huge cost.
Working physically together, in the same space, as a whole team, can be extremely enabling. Supporting a joyful environment. Sadly, too many offices were (and remain) environments hostile to collaboration. Return to those hostile environments has been imposed on many.
It makes me sad to see people…
…forced to return to offices that are noisy, cramped, illness-spreading, collaboration-killing environments.
…conversing over video chat from across the same open-plan office, because while they’re in the same space it’s not set up to help them collaborate.
…excluded from teamwork because the rest of the team is in another location.
…stuck waiting on pull request reviews from people they are sat right next to.
Most of all I get sad when I see ineffective teams with no ability or motivation to improve—whether remote or co-located.
For many teams there can be huge advantages to co-located working, but these aren’t it. Different approaches better support different people, different teams, different contexts.
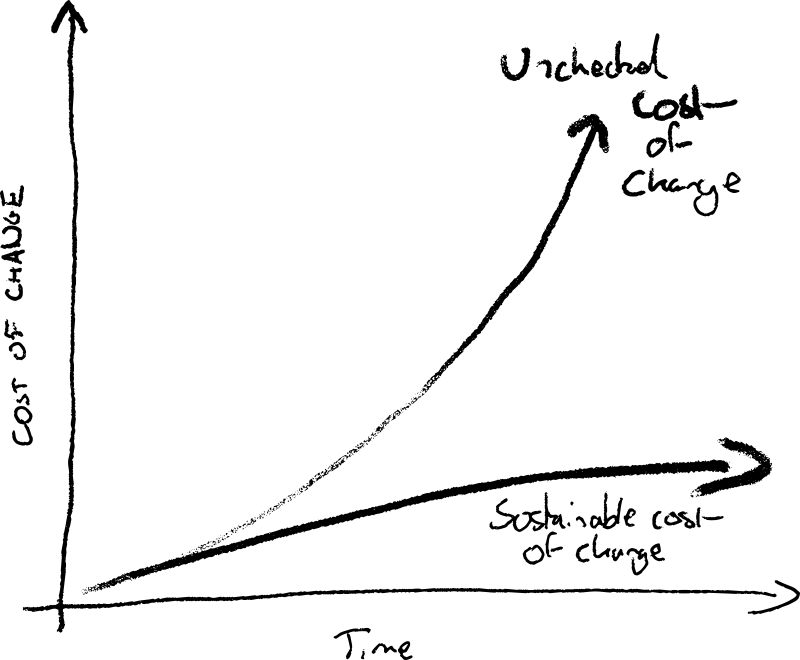
Return to office mandates can destroy the effectiveness of teams who have uncovered better ways of working by going remote.
Tearing your teams apart and undermining their ways of working are tremendously damaging. Fabled watercooler serendipity will not make up for this.
You’ll cause harm by forcing RTO on teams with cultures that benefit from remote. Please, instead, help your teams craft their best environment.
Remote isn’t always Best
Many people are very passionate about remote work. Remote can bring inclusion benefits. Offices can bring communication bandwidth benefits.
This claim crossed my feed this week:
“Every successful company needs to have the most talented people. The most talented people no longer live in, or want to live in the same place.”
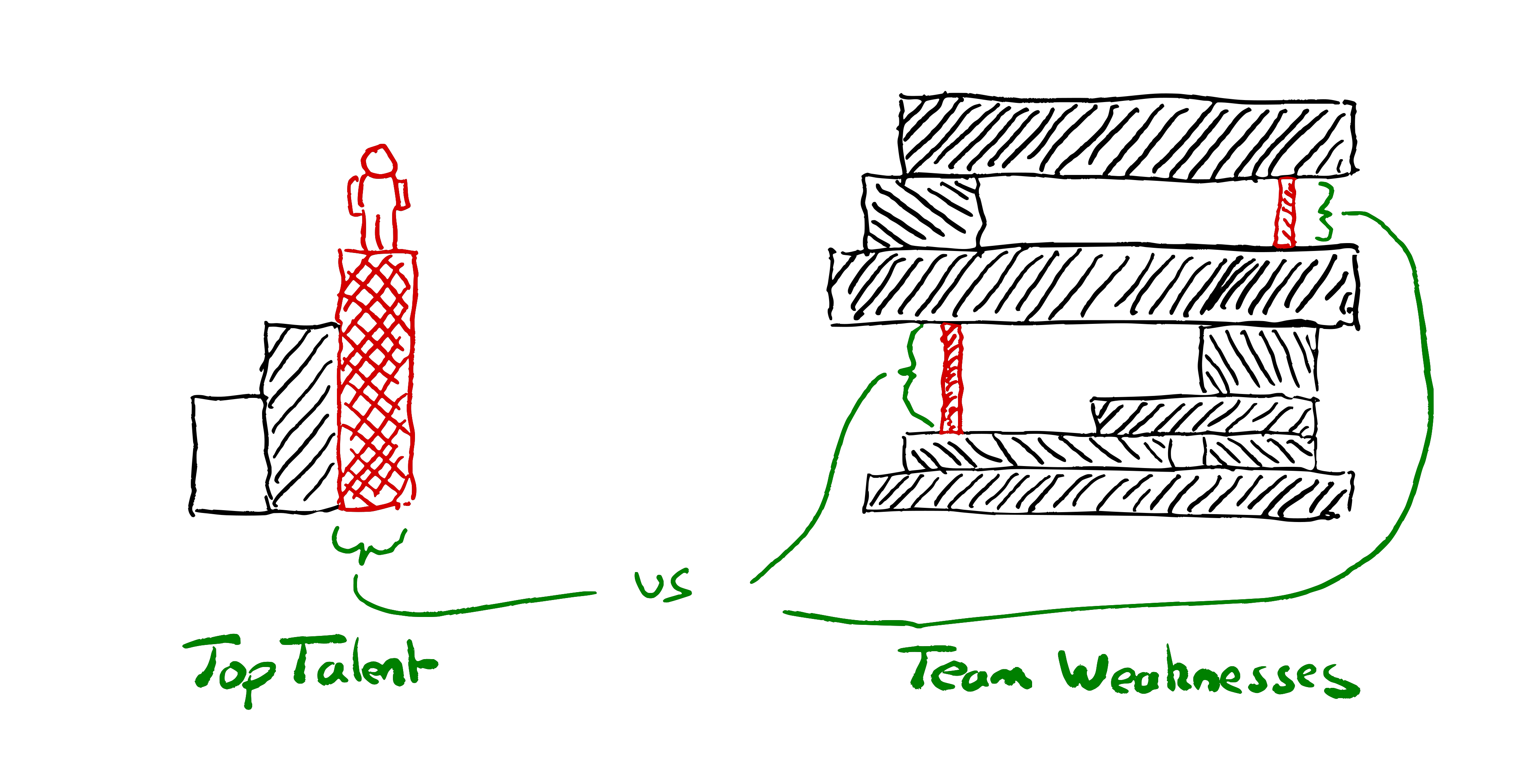
This suggests that “acquiring” talented people is a zero-sum game. It’s not.
Rather, successful companies maximise what their people can achieve. One factor is indeed how talented the people who join are. Another is their pre-existing skills. Even more significant than these is the extent to which the organisation amplifies & accelerates, or impedes their abilities.
Different organisations, and different ways of working, are more or less suited to make different individuals the most effective.
Don’t Compromise
Mediocre teams compromise on their ways of working to avoid conflict; sacrificing their team’s potential on the altar of individual autonomy.
Effective teams find ways of working that give themselves an advantage. They shape their environment to maximise their effectiveness.
Mediocre teams compromise on their ways of working to avoid conflict; sacrificing their team’s potential on the altar of individual autonomy.
Hybrid work policies can easily result in the downsides of being anchored to an office location, with none of the benefits that could come from having everyone together.
It doesn’t just happen with location. Individual preferences for working exclusively in certain parts of the codebase can result in nobody working together towards the same mission. People who feel they get more done if left to their own devices for days or weeks are often right, and it can also be true that the team as a whole is less successful.
It’s easy to avoid conflict and get stuck in mediocrity. Optimising for individual happiness can result in less of the joy that people find in teams that achieve great things together.
Optimising for individual happiness can result in less of the joy that people find in teams that achieve great things together.
If only effective collaboration had such an easy answer as asking everyone to come to an office.
If you want to build up your teams rather than undermine them, start with curiosity about how they work. Invite and support them to uncover better ways of working for them. What helps them. Their preferences. Their lives. Their mission. Their constraints.
I’m privileged to have experienced working with many effective & ineffective teams & communities. Both in office environments and remotely, with a variety of collaboration styles.
I’ve experienced some of my most joyful work in teams working together in the same space. I’ve benefited from flexibility and inclusion with remote work. I’ve also been able to contribute as part of larger open source communities where I couldn’t even know everyone by name. There are plenty of reasons to be passionate about each approach.
What I am most passionate about is teams finding the most effective ways to work together. Joy for the individuals involved. Successful team missions. Turning the constraints they’re working with to their advantage.
Beyond a Binary Debate
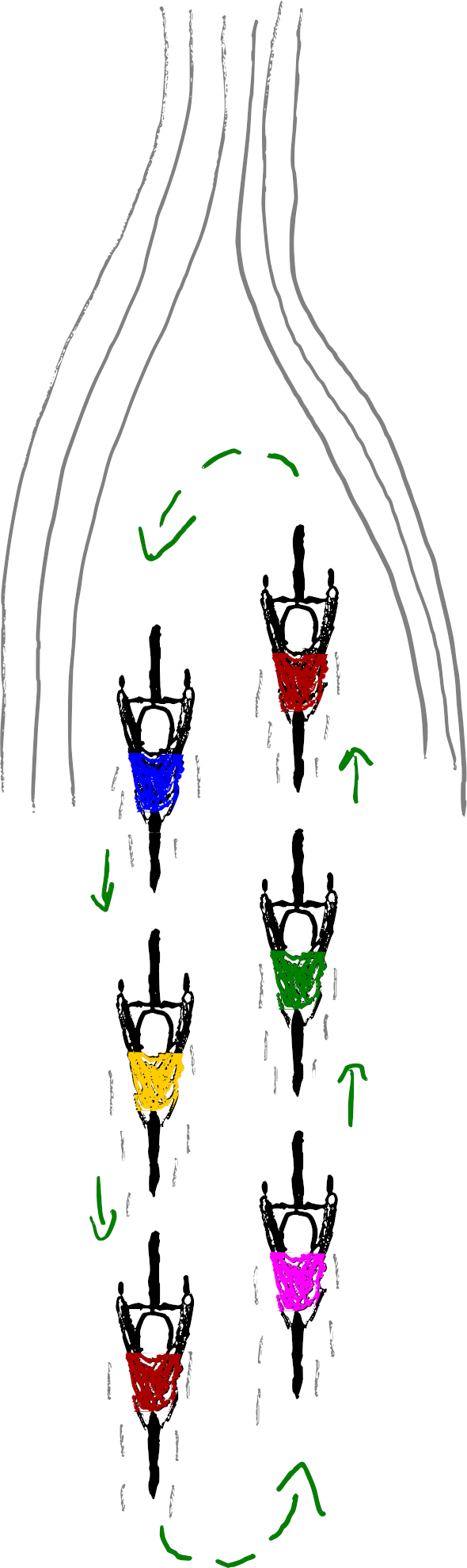
There are more options than just Office vs Remote. Distributed vs Co-located working is often conflated with Async vs Synchronous working styles. It’s not one or the other.
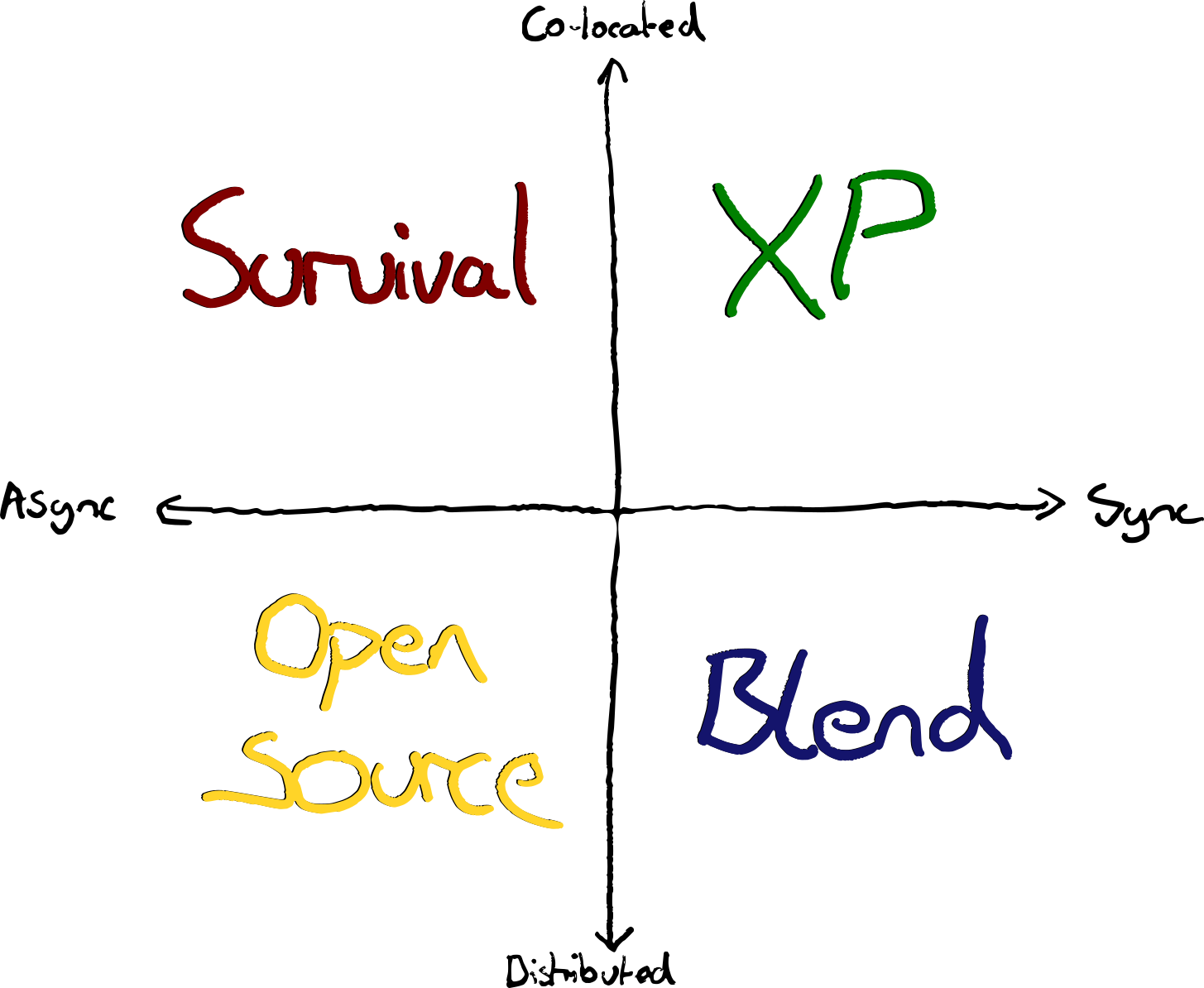
By Async I mean working independently. Coordinating via tickets, pull requests, mailing lists etc.
By Sync I mean working together, on the same thing, at the same time—and not necessarily at the same place.
Those who’ve experienced greatness at one extreme on this chart are often enthusiastic. Top-right and bottom-left have many proponents. However, bottom right can be glorious as well, and this seems to be less discussed. Fans of Async-Remote sometimes characterise Sync-Remote as being “unable to let go of the office”. However, I’ve seen it work tremendously well—often far better than the typical office space allows.
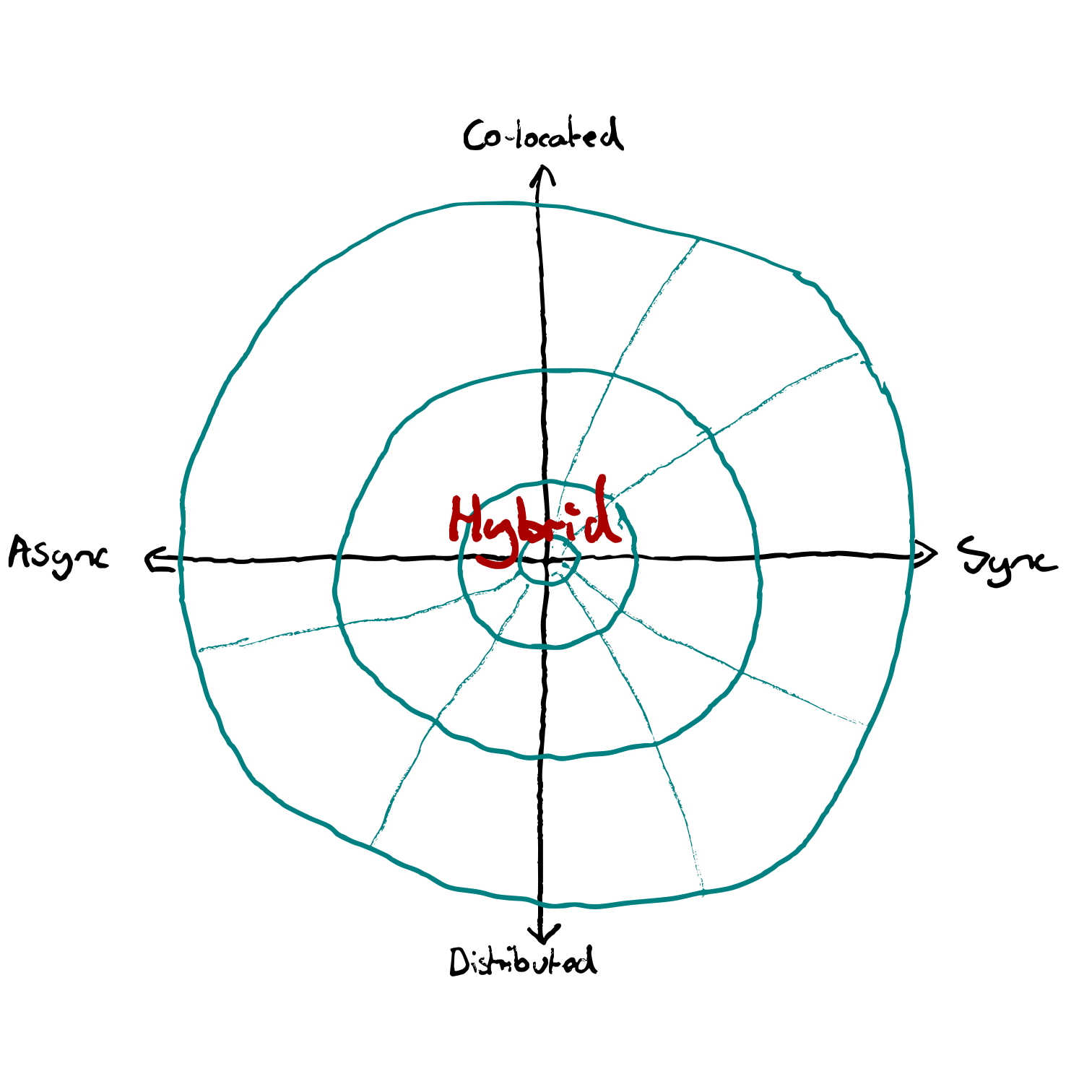
Teams often compromise somewhere near the middle. A hybrid of workplaces and work-ways. Accommodating a variety of preferences and needs.
The best teams I’ve seen move towards an edge and find a sweet spot. You can imagine a third dimension of effectiveness. With a pit in the centre.
Office and Async — Escape the Tragedy
I’ve not found a scenario where this quadrant is better than an alternative, despite it being, in my experience, the most common for most “teams”. Where teams are acting more like a mere convenient grouping of individuals than a collective with a common mission.

Don’t suffer and merely survive, aided by your noise cancelling headphones.
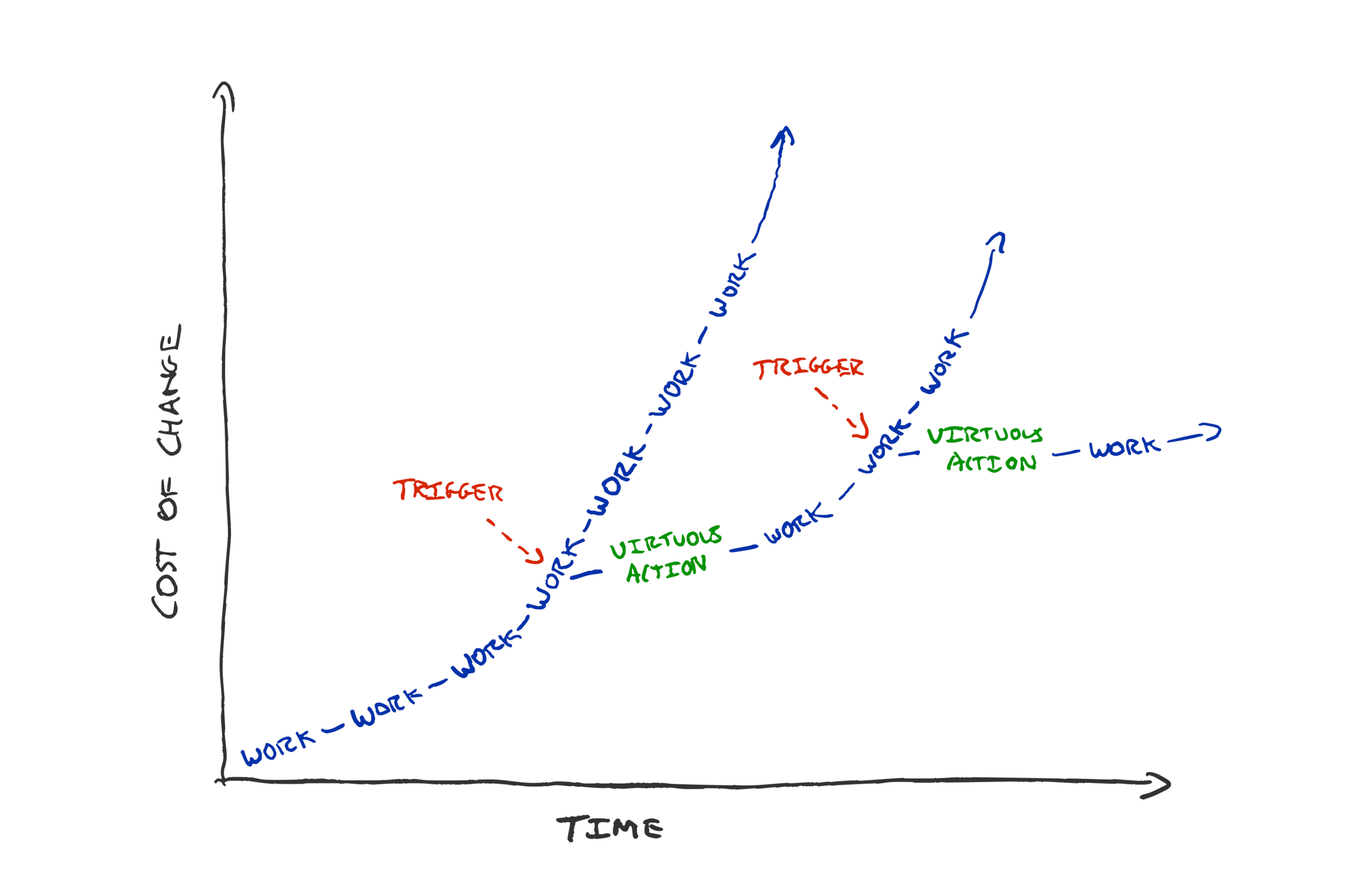
This scenario often arises through compromise on ways of working that are the least objectionable to everyone in the team. In contrast, better ways of working tend to arise from finding what works and turning it up to the extreme.
I’m interested to hear from you if you have seen a team better off in the Office & Async quadrant than they would be in another.
If you’re stuck in this quadrant, and you’re not finding it joyful, consider a move to another. Don’t suffer and merely survive, aided by your noise cancelling headphones.
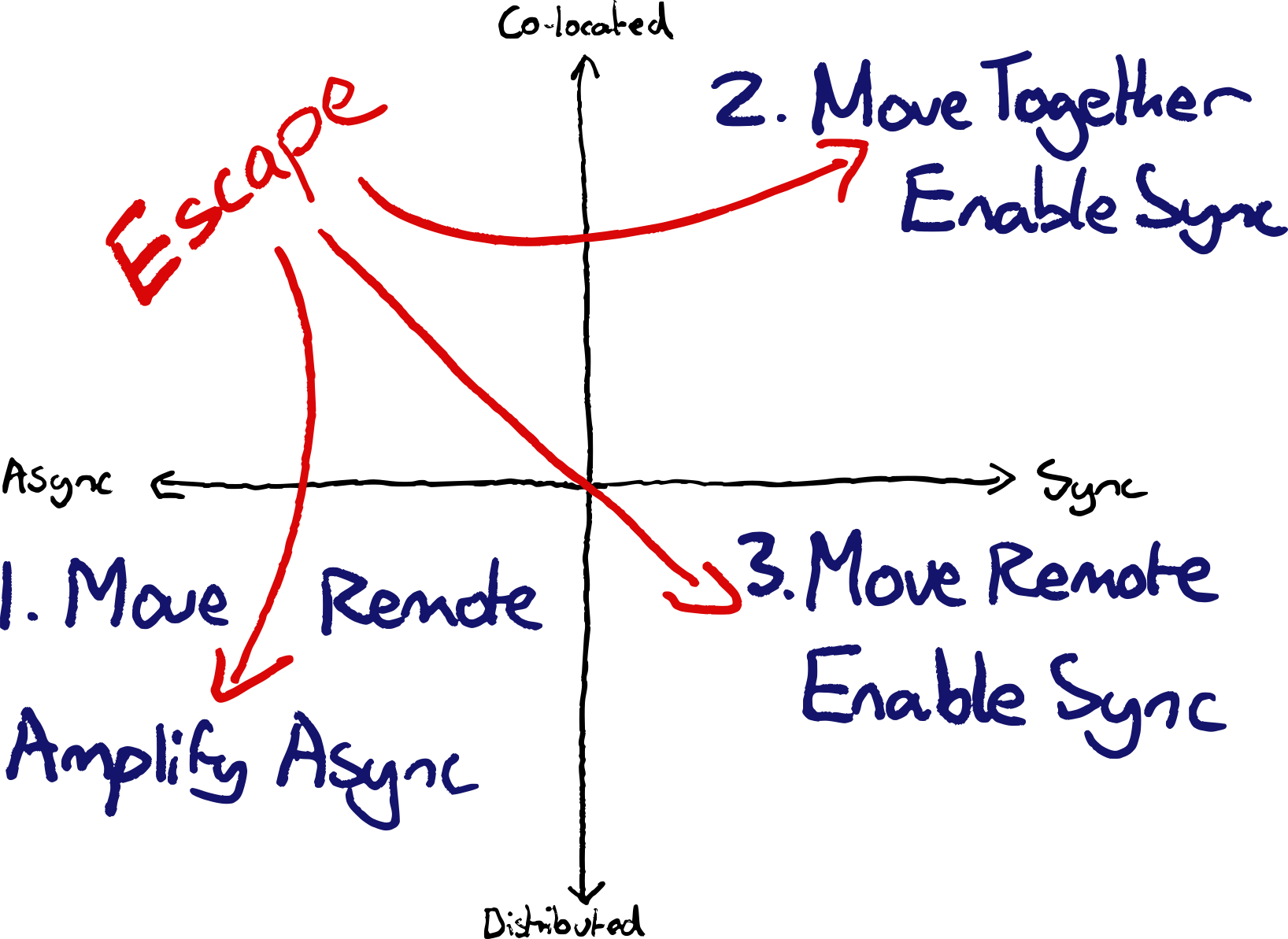
Option 1: Move remote, to get the true benefits of Async
If you have the luxury of working remotely, and you prefer working asynchronously, then remote will open up lots of benefits.
You’ll avoid commutes. You’ll enable hiring from anywhere, including a wide geographical spread, making it easier to hire great people. You’ll increase timezone coverage for progress that never stops and improve operational coverage.
Option 2: Move together, to enable Sync
If your team are all spread out within the same office, bring your desks together. Control your space as much as possible. Use the wall space. Separate your area with whiteboards / soundproofing.
If this isn’t possible, consider booking meeting rooms out where you could go to work together. It’s amazing how infrequently large meetings get questioned. Whereas making small changes to enhance the space you’re working in sometimes alarms bureaucracies.
Working in the same space will enable ad-hoc discussions. It facilitates pair programming with regular rotations. You can make the things most important to you visible in the workspace. You’ll also overhear opportunities to help each other.
Option 3: Move remote, to enable Sync
If you can’t move your desks but have the luxury of working remotely, you could move to the bottom right to make collaboration easier. Then try some of the ways of working mentioned below.
Remote and Async — Open Source Style
Many of the best ways of working in this quadrant have emerged from the ways that distributed open source communities work. Pull requests. Mailing lists. Decision frameworks based on written proposals.
This style enables large groups of people to collaborate effectively to achieve large things. Often larger than a traditional team could achieve. Sometimes at the cost of speed of decisions.
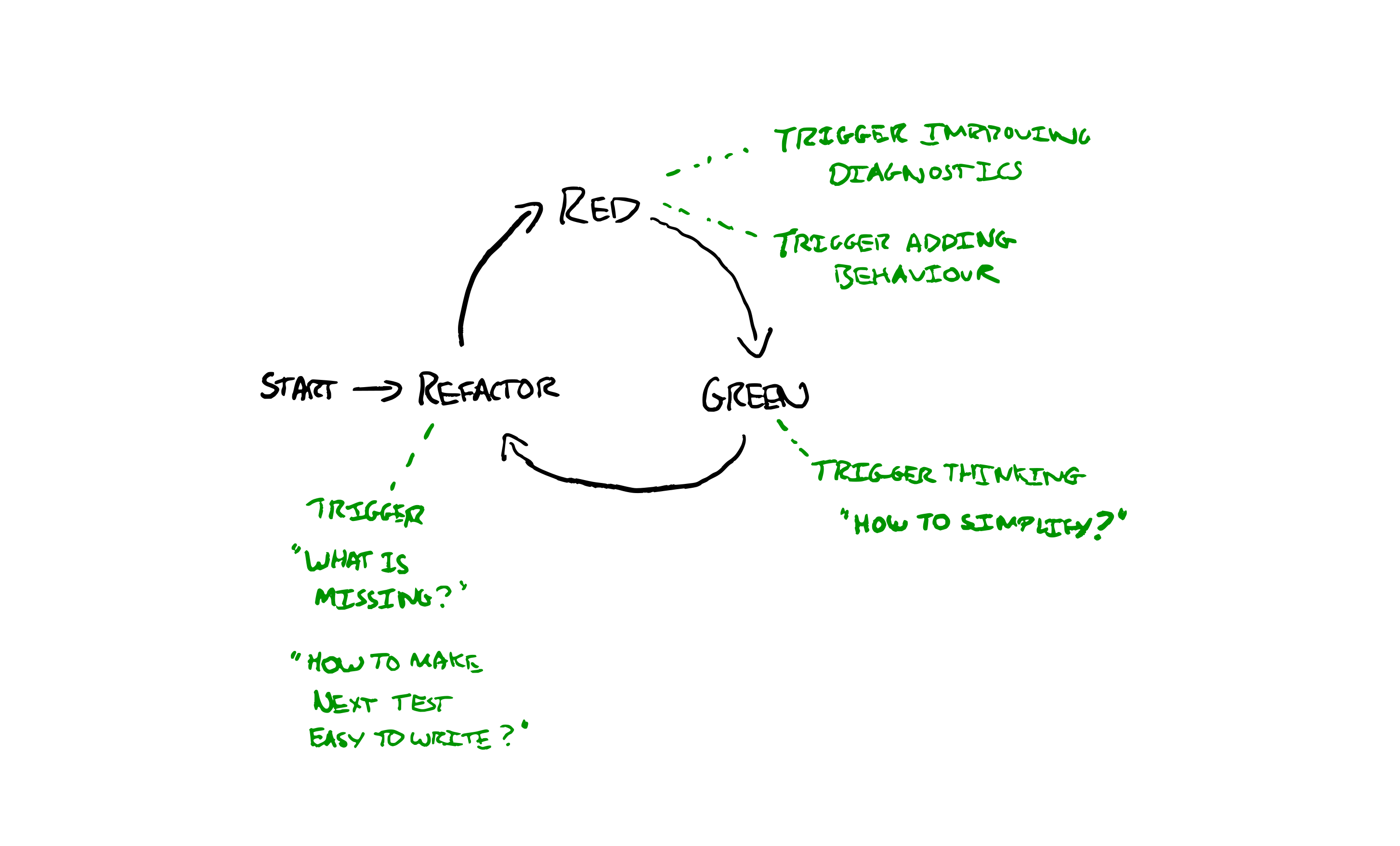
Office and Sync — XP Style
Extreme Programming Practices are a great starting point for office & sync. Then experiment and iterate towards what works best for you.
If you have the luxury of being in the same space—be in the same space. i.e. get your desks together. Get big desks so you can sit and work together. Customise your space to be informative & facilitate collaboration. Track things on the walls. Keep living diagrams on whiteboards. Put up big displays with production metrics.


One of the nice things about using a physical whiteboard as the information radiator in a team was
— Benji Weber :: @benjiweber@mastodon.social (@benjiweber) February 13, 2022
a) the ease of modifying the process visualisation and
b) the reinforcement of the constant reminder
Subtle effect from opinionated tools like Jira/Trello is stifling this. pic.twitter.com/HJeqeZR7t0
Remote and Sync — Learn what works
Less has been written about this quadrant. Kent Beck wrote this article recently which partly inspired this post.
During the pandemic I saw several teams stuck in the Async-Colocated quadrant discover the benefits of collaborative practices.
re-discovery of XP practices unimpeded by hostile offices
Teams stuck working as isolated individuals within the same office were freed. Absent the noisy office environments where they were artificially separated, they could start working together, in a remote-first way.
Teams discovered new ways. These included re-discovery of XP practices unimpeded by hostile offices.
Eliminate wasteful Meetings
I saw teams inverting what they used synchronous time for. Things they did together through mere habit, like status updates for stakeholders, became async. Boring meetings of status updates that could be slack messages became slack messages.
Instead, sync time was protected for actual collaboration. The higher cost of sync time when remote due to lower bandwidth incentivised using it more wisely.
Always-on Zoom
An always-on video call for teams allowed people to drop in and out to work with each other and catch up on work others were doing in parallel. Analogous to a dedicated team war-room in an office. Without the bureaucratic hurdles to setting one up. Nor the challenge of competing with nearby teams for noise.
Dashboard Nudges
Automated daily screenshots of dashboards with team KPIs. Regular snapshots sent to teams’ Slack channels replaced the physical TVs from the physical office. These nudges provoked conversation, increasing awareness of both the success of features, and production risks.
Team Games
Opportunities to relax and have fun together needed to be intentional. Web based multi-player remote games were a go-to for several teams.
Virtual Whiteboarding
Discussions and brainstorms sometimes worked even better than their in-person alternatives. Unlike physical whiteboards, in virtual space there’s no problems with everyone crowding around. Nobody can hog the view. Everyone can participate at once. Not to mention saving a fortune in post-it notes.
Pair Programming
Pair programming works well when remote. For many teams it works better remotely; their office environments being so hostile to in-person collaboration. No longer having to compete with the din, pairs could focus.
Communication bandwidth isn’t as high as in-person, but the tooling to work together remotely has come a long way. Tools like VSCode Live-share, and Tuple make working together a breeze. Tooling like mob enables fast handover.
Continuous Integration
True continuous integration (integrating to main multiple times per day) is even more valuable when you don’t have the opportunity to overhear what others are working on.
Serendipity is not a Strategy
All quadrants benefit from intentionally defining and writing down ways of working, rather than relying on accidental interactions and happenstance in an office.
Don’t rely on watercooler moments.
If you want folks to have unstructured conversations from which new ideas might emerge, create those opportunities intentionally. There are lots of mechanisms to increase luck and the chances of useful conversations occurring. e.g. No-pre-planned meeting days. Blocked lunch breaks. Group volunteering. Team meals. Quarterly Offsites. Retrospectives.
Look for what’s working for your team and turn it up. Try changing things and uncovering better ways of working!